电源
91篇文章

我们今天探讨C语言变量的定义和初始化。那么我们首先要明确三个问题。第一,我们要明白什么是变量,或者为什么C语言一定要有变量;第二个在C语言中如何去表达这些变量,或者说C语言都有什么类型的变量如何定义这些变量;第三,变量为什么要初始化,以及如何初始化。
第一个问题,关于变量,一个最通俗的理解就是变化的量。本来外在的物质世界就是在不断变化的,不是有句话么:“唯一不变的就是变化”。C语言作为描述客观世界变化的一种语言,首先就是要有能够对外界事物变化状态量化的工具,那么这个工具就是变量。数字世界,首先就是量化,这个是一切后续工作的基础。
我们下面拿几个常用的变量类型进行说明,比如char型变量,它主要是用来应对0 – 255之间变化的事物的,比如字符什么的。比如float,浮点型的变量,它主要是量化客观世界中模拟量的事物,比如汽车的速度、太阳光的强度等等;再比如int型的变量,它的描述范围就比char型大得多了,它主要是应对整数变化的客观事物的,比如学生的个数、苹果的个数等等。
那么实际上,我们说C语言的变量远不止这些简单的数据类型,是吧。我们还有数组,结构体,还有指针、栈、链表等等。每种数据类型的出现都是为了解决一个量化的问题,比如指针,它主要是定位量化计算机中内存寻址问题;比如结构体,它的定位主要是用来描述复杂事物的,就比如汽车,它不仅有行驶的速度,还有轮子的个数,椅子的个数等等;再比如栈,它的主要作用是解决任务切换以及函数调用时,程序现场的保护问题。
那么也就是说每一个变量类型或者量化工具类型的出现,都是有原因的,都是为了解决实际问题的。当我们从这个视角去看这些变量类型和必要性的时候,我们的理解就会深刻很多。举个例子,比如面向对象数据类型的产生,就是把方法或者函数集成到了一个类型中,这样就可以更为准确的去描述客观事物,比如一个狗狗,它不仅有一条大尾巴,还可以跑得非常快,大尾巴是数据,会跑且跑得快是方法。面向对象的语言比如C++或者Java,就把这些变量和方法封装起来,形成一个新的更为综合的量化工具,那就是对象。
站在C语言的基础上,往上看是C++语言等面向对象的,但是如果往下看,比如到了汇编级别,就是另外一番场景。我们知道汇编语言是最接近机器的语言,对于某一类型的单片机,它一般有几十条特定中汇编指令。但是我们说汇编语言是没有数据类型的,它操作的只有二进制类型的数据,并没有对这些数据进行按照其属性进行分类。没有根据属性对数据进行分类,其实也就是说没有对量化工具进行分类,那么人类的大脑就要耗费更多的能量去理解汇编程序,人的大脑本身都是很懒的,能省能量肯定是想办法节省能量。从这个角度上的看,汇编语言更像是机器语言。
但是我们说电脑本身就是机器,不同汇编语言的指令集才能真正反映各个芯片架构的不同,指令集不同可能对应的电路也是不同的。任何高级语言最后还是要在特定的机器上运行的,那也就是说这些高级语言最后还是要翻译成特定的汇编语言。这个翻译的工作就是编译器要做的事情。另外,软件的开发还要有量好的代码编辑环境以及调试环境(比如支持单步调试,实时查看寄存器及存储单元的数据),所以一款新的单片机是不是好用会有多方面的因素影响的,也不能只看指令集的执行效率。
第二个问题,C语言都有什么类型的变量呢?我们可以用一张表来大概描述一下,下面这张表对C语言的数据类型进行了相对完整的总结。大家可以看一下,整体的数据类型被划分为四类:基本类型,构造类型(组合类型),指针类型还有空类型。基本的数据类型肯定是根本,C语言在级别数据类型的基础上构造出更为复杂的数据类型,用于描述相对复杂的事物,比如结构体等等。那么C语言就是使用这些相对抽象的基本类型,去量化和描述纷繁复杂的外部世界的。我们在前面已经提到了绝大多数数据类型产生的原因,这里就不再赘述了。如果有还不理解的同学,可以自己上网去查一查资料。
从下面这幅图可以看出,不同的基础数据类型器长度是不一样的,而且同一种数据类型在不同的机器和编译器编译下其数据长度也是不一样的。不同的基础数据类型,所占据是二进制数据位数发生不同,这个是可以理解的。对于相对简单的事物,比如字符,本来就不需要使用那么长的位数来表达,这个是基本诉求。再一个,比如对于char类型这种需要较少位数就可以表达的可以量化的事物,如果使用int这种长度的数据去表达,本身也是对计算机存储资源的浪费。基于上述两个原因,才出现了不同的数据类型有不同的长度的现象。我们在实际编程的时候,从设计的角度上来看,肯定是选择使用最少的存储位数来量化自己要描述的事物,这样占用的资源才能是最少。当程序代码行数非常多的时候,这种差异就会相对非常明显了。
下面,我们来探讨第三个问题,变量为什么要初始化以及如何初始化。我们首先解释一下为什么单片机数据最好要初始化。众所周知,变量是存储在RAM中,掉电后即丢失,上电后默认全为0。那么这样的话没赋初值的变量值全为0,这也应该是大家认为理所当然的。但是实际上并不是这样,有些类型的单片机,当单片机复位的时候(包括硬件复位即按下复位按钮,看门狗复位,以及其它软件程序复位),单片机只是重新跳回到main函数开始执行,而并没有清空RAM!所以,那些只是定义而没有赋初值的变量(尤其是全局变量)依然会使用复位前留下来的值!那么这样,程序运行可能就会出现异常的结果,尤其是指针变量。数据有一个初始的值,整个程序也就有了一个初始状态,初始状态确定了,如果程序设计得没有问题,那么就可以按照既定的规则跑下去。如果程序错误发生在初始位置上,那就太可惜了。大家在编程的时候,一定要注意这个现象。
那么下面我们看一下,如何对变量进行初始化。不同的变量类型,初始化的方式肯定是不一样的。首先对于基础的数据类型,可以直接初始化成想要的值即可。那么对于数组、结构体等类型,初始化的方法就具体问题具体分析,各具特色了。我们下面举例子进行说明。
一维数组:
int a[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int a[10] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
int a[10] = {0};
int a[] = {1, 2, 3, 4, 5};
二维数组:
int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
int a[3][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
int a[3][4] = {{1}, {5}, {9}};
/*
1 0 0 0
5 0 0 0
9 0 0 0
*/
int a[3][4] = {{1}, {0, 6}, {0, 0, 11}};
/*
1 0 0 0
0 6 0 0
0 0 11 0
*/
int a[3][4] = {{1}, {5, 6}};
/*
1 0 0 0
5 6 0 0
0 0 0 0
*/
int a[][4] = {{0, 0, 3}, {}, {0, 10}};
/*
0 0 3 0
0 0 0 0
0 10 0 0
*/
字符数组:
char c[10] = {'I', ' ', 'a', 'm', ' ', 'h', 'a', 'p', 'p', 'y'};
char c[2][3] = {{'y', 'o', 'u'}, {'a', 'r', 'e'}};
char c[] = {"I am happy"};
char c[] = "I am happy"; // 可以省略花括号
char c[] = {'I', ' ', 'a', 'm', ' ', 'h', 'a', 'p', 'p', 'y', '�'}; // 与上面等价
char *p;
p = "I love China"; // 正确
char c[14];
c = "I love China"; // 错误
c[14] = "I love China"; // 错误
结构体:
struct {
char name[20];
int age;
}student1, student2;
//匿名结构体
struct Student {
char name[20];
int age;
}student1, student2;
//声明结构体
struct Student {
char name[20];
int age;
}student1 = {"xiaoming", 20};
struct Student student1={.age=12}; // C99可以只对age进行初始化,其他变量初始化成零
联合体:
union Data {
int i;
char ch;
float f;
}a = {1, 'a', 1.5}; // 错误,不能同时初a.ch = 'A'; // 正确
对共用体赋值要指明赋值对象,如
a.f = 1.5; // 正确
a.i = 40; // 正确
a = 1; // 错误,没有指明赋值对象始化3个
union Data a = {16}; // 正确
union Data a = {.ch='j'}; // 正确 C99新增
枚举:
第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。
声明
enum Weekday {sun, mon, tue, wed, thu, fri, sat};
定义
enum Weekday workday, weedkend;
赋值
enum Weekday {sun=7, mon=1, tue, wed, thu, fri, sat};
// sun=7, mon=1, tue=2, wed=3, thu=4, fri=5, sat=6
把上述三个问题到搞清楚后,我们的这篇文章到此就结束了。
参考资料
① C语言数据类型总结 https://blog.csdn.net/xingjiarong/article/details/46942649
② C++继承 https://www.runoob.com/cplusplus/cpp-inheritance.html
③单片机C语言探究--为什么变量最好要赋初值 https://blog.csdn.net/weixin_34342207/article/details/92999746
④ C语言-定义与初始化总结 https://blog.csdn.net/syzdev/article/details/103532435

我们使用的单片机是深圳睿思芯科公司出品的Pygmy-E系列的单片机,它是面向IOT超低功耗32位SOC,内含睿思独立设计的ORV32 RISC-V内核,实现了RV32IMC标准指令扩展。主要用于IOT终端设备的感知、控制、连接等领域,如智能家居、智能控制、智慧工业、智慧园区等。
这款单片机主频可以高达100Mhz。在存储方面,一级缓存8KB,二级缓冲256KB,存储容量还是比较大的。同时它支持丰富的外设接口,比如GPIO,UART,SPI,IIC等,可以实现复杂的通信及控制功能。
在低功耗方面,Pygmy-E拥有极低的功耗表现,通过对CPU极致的低功耗微架构设计和对SoC系统层级进行深度优化设计,动态功耗远优于同等计算性能的ARM芯片,并且实现的uW级别的SOC待机功耗。
整个处理器的框架图,是如下这个样子,供大家参考。
我们后面会分几个模块来介绍这款单片机,比如GPIO接口、I2C接口、SPI接口以及中断系统等等。这篇文章里面,主要介绍系统时钟以及GPIO接口的一个关键点,介绍这个的时候,我会尽可能的和ARM架构的单片机进行比较,在对比中把这款单片机架掌握得更加深刻。
整个系统主频和外设的频率(SysTick定时器,UART,I2C,SPI等)是可以自己设置的,不过从目前我这边拿到的资料来看,在时钟树这块,它的架构不像ARM内核那样可以通过对RCC寄存器的配置来统一对时钟进行管理。
不过这并不影响单片机的使用,只是在配置时钟这块需要对各个外设寄存器有更加深入的了解,因为外设时钟信号的配置更多是在这里进行的。
我们这里外部使用的是20Mhz的有源晶振,实际系统中的主频也就配置成了20Mhz。
这款芯片的外设使用的是新思科技的模块,对GPIO口复用的配置主要是通过各个接口的SEL和DIR两个寄存器来实现的。SEL和DIR寄存器的值都为0的时候,使用的是复用模块的功能;SEL和DIR寄存器中的值均为1的时候,单片机使用的是GPIO口模块的功能。但是每个接口模块,只能有一个复用功能,这个地方不同于我们经常使用的STM32单片机。在STM32单片机中,大部分接口都会支持好几个功能模块的复用。
从上图中,大家可以看出来每一个端口目前只有一个复用功能,我们在实际进行端口配置的时候,灵活度相对来说要小不少。
大家可以看一下GPIO模块的通用框图。
从这个通用框图,可以看出来,GPIO输入和输出值的改变,是通过D触发器完成的。用硬件原理上来说,如果GPIO接口的模块没有时钟信号,那么这个模块就不能够工作。我们可以直接通过控制时钟模块就可以控制响应接口是不是处于工作,这样就可以达到控制整个芯片功耗的目的。但是我们在一般的ARM单片机提供的参考手册中看不到这样的框图,这个框图中对D触发器的解释相应地来说,会更加清晰。
大家好,我是张飞实战电子张角老师!
所有通信协议,应该都是一个速度、成本的折中,这里的成本包括完成通信所占据的接口资源(或者说需要几根线)以及硬件电路模块设计的复杂度。
我们前面分析过,如果想要实现高速的数据通信,通信双方的时钟是必须同步的,否则可能会出现数据错位的情况,尤其是通信双方本身的时钟频率相差较大的时候。那么自然的,uart作为一种异步通信协议,它的传输速率肯定不会太高,或者说肯定是小于同步通信协议的。反过来说,如果异步通信协议采用采用发送方或者接受方中的一个时钟频率,作为通信的波特率,那么在两者的时钟频率相差较大的情况下,一定会出现数据错配的情况。甚至有可能,每次传递8个数据都不一定传输得了。信号传输的波特率降低了以后,可以降低对通信双方频率相差的要求,反正最后都要把自身的频率和波特率之间进行一次转换,归一到统一的波特率上来。但是归一化之后依然会有误差的,这个我们前面讨论过,所以依然不能每次传递较多的数据。再加上,uart通信协议中,各种辅助位占据了一定的资源(大约25%),数据传递的速度肯定就更慢了。
虽然uart传输的速度相对较慢,但是如果只是单向通信的话,着实相对来说,非常简单。只需要两根线就可以了,一根Tx就行(大多数情况下,通信的双方都是共地的)。
那么现在我们达成了共识,如果要进行高速的串口通信,必须在通信的双方之间进行时钟同步。那么SPI和I2C这两种协议,应运而生了。那么SPI和I2C有什么区别呢?我感觉这两个有点像TCP和UDP的区别一样,TCP有校验和握手机制;UDP则没有,只是不管不顾发数据。具体表现就是I2C是有应答机制的,但是SPI没有,那么自然I2C这种通信协议的传输速率是没有SPI快的。再一个,在I2C通信中,不管是读指令还是写指令,首先进行的是不是寻址呀,找到相应的芯片以后,才能进行下一步的数据传输,是吧。但是SPI就不用搞这个操作,它是通过硬件的片选信号之间指定从机的,从地址寻址上看,它的速度要远比I2C高。还有一个,不管是读数据还是写数据,一般都是还还要再指定寄存器的地址,然后主机才能通过SDA总线去读取从机中的数据,但是SPI一般是直接通过指令读取相应的寄存器,这中间又少了一次寻址的过程,那么有效数据传递的速度相比I2C,肯定是高了许多。
从通信双工的角度来讲,SPI还支持双工通信,那数据传输的速度就更快了,在这个方面作为半双工通信的I2C自然是更比不了。
虽然传输速度,I2C比不上SPI,但是I2C也是有自己的优点呀,那就是占用的端口资源更少。只要两根线就行了,一根数据线,一根时钟线,就足够了,就可以实现双向通信了。但是SPI可不行了,SPI要实现这种双向通信,至少需要四根线,CLK,MOSI,MISO,CSS。俗话说,一分价钱一分货,此言不虚。
I2C和SPI都是可以实现点对多点进行通信的,既然要实现点对多点进行通信,那么就必须解决寻址的问题。SPI,我们说过了,仗着自己数据传输速度快的优点,财大气粗,对每一个从机都安排了一个片选信号线。这种操作,着实占用了不少单片机的接口资源。但是I2C就不行了,因为数据传递的速度相对较慢,自然得节省开支,包括在点对多点的寻址上也是如此。I2C通信协议是通过地址码的方式来解决多机寻址问题的,这个就有点像SPI的片选线。
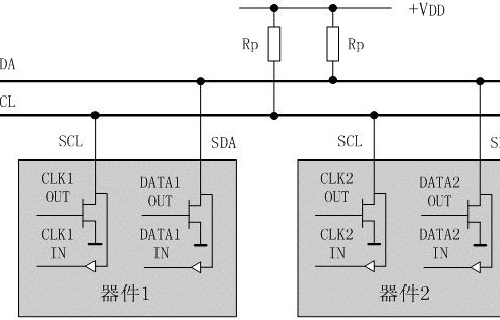
系统中的所有外围器件都具有一个7位的"从器件专用地址码",其中高4位为器件类型,由生产厂家制定,低3位为器件引脚定义地址,由使用者定义。主控器件通过地址码建立多机通信的机制,因此I2C总线省去了外围器件的片选线,这样无论总线上挂接多少个器件(当然终端在要在有效个数范围内),其系统仍然为简约的二线结构。终端挂载在总线上,有主端和从端之分,主端必须是带有CPU的逻辑模块,在同一总线上同一时刻只能有一个主端,可以有多个从端,从端的数量受地址空间和总线的最大电容 400pF的限制。
基于IIC总线的物理结构,总线上的START和STOP信号必定是唯一的。如果同时又两个设备同时发起数据传送怎么办?这就涉及到时钟同步和SDA仲裁的问题。我们这里注意到SDA和SCL都是开漏输出设计,那么自然SDA和SCL都具有线与功能。在SCL总线上只有所有的设备的SCL都为高的时候,SCL才为高,只要有一个为低,那么SCL就为低。不管怎样,所有从设备设备的SCL总是同步的。要么是高,要么是低。
那么SDA的仲裁问题是怎么回事呢?SDA线的仲裁也是建立在总线具有线“与”逻辑功能的原理上的。节点在发送1位数据后,比较总线上所呈现的数据与自己发送的是否一致。是,继续发送;否则,退出竞争。这里的比较功能是I2C设计的亮点,有了这个功能为基础,SDA的总线仲裁才能是自动执行的。SDA线的仲裁可以保证I2C总线系统在多个主节点同时企图控制总线时通信正常进行并且数据不丢失。总线系统通过仲裁只允许一个主节点可以继续占据总线。
上图是以两个节点为例的仲裁过程。DATA1和DATA2分别是主节点向总线所发送的数据信号,SDA为总线上所呈现的数据信号,SCL是总线上所呈现的时钟信号。当主节点1、2同时发送起始信号时,两个主节点都发送了高电平信号。这时总线上呈现的信号为高电平,两个主节点都检测到总线上的信号与自己发送的信号相同,继续发送数据。第2个时钟周期,2个主节点都发送低电平信号,在总线上呈现的信号为低电平,仍继续发送数据。在第3个时钟周期,主节点1发送高电平信号,而主节点2发送低电平信号。根据总线的线“与”的逻辑功能,总线上的信号为低电平,这时主节点1检测到总线上的数据和自己所发送的数据不一样,就断开数据的输出级,转为从机接收状态。这样主节点2就赢得了总线,而且数据没有丢失,即总线的数据与主节点2所发送的数据一样,而主节点1在转为从节点后继续接收数据,同样也没有丢掉SDA线上的数据。因此在仲裁过程中数据没有丢失。
这里大家注意一下,SCL同步与SDA仲裁是同时发生的,不存在先后问题。这些实现都是由于I2C设备的特殊设计实现的,堪称非常优雅。
大家好,我是张飞实战电子张角老师
讲完了基本的外设接口,我们今天看一下这个开发板的中断系统。中断系统可以说是单片机能够响应任务需求的核心机制,对于一个固定的单片机而言,计算资源只有那么多,如何高效地利用这些计算资源,是单片机设计者必须回答的问题。目前主流的方案,就是我们今天要讲的中断系统。我们可以人为给不同的中断请求设定不同的级别,这样单片机系统就知道执行任务的轻重缓急了,系统的实时性提高了,计算资源就相当于被高效地利用了。
那么,在嵌入式实时操作系统中,任务又是一个什么概念呢?我们知道,任务也是有优先级的,不同的任务优先级是不同的,那任务的优先级和中断的优先级是什么关系?我觉得,可以把任务理解成一种不靠硬件抢占执行的中断,应该归入大中断的概念中去,本质上是进一步提升了单片机响应任务的实时性。我们知道,一般中断程序的执行时间都不宜太长,只是负责变量打标,然后快速退出就可以了。一个高中断优先级的中断程序,执行得太长的话,那么所有相应的低优先级的中断程序是不是就完全无法执行了。所以程序开发的时候,才尽可能地让中断程序只是负责对变量打标而已。中断程序对相应的变量打标以后,实际工作的执行,还主要是任务的调度来实现的。这样的设计,相比而言能够让计算资源的实时性得到最大程序的发挥。这个也是嵌入式实时操作系统被设计出来的一个关键的原因。
鸿蒙系统外部中断,到底是怎么样被初始化的呢?
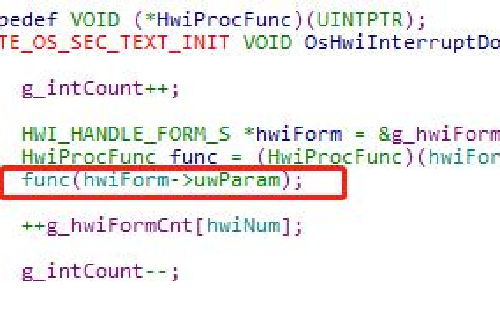
上图中,第一个红框里面代码的意思就是开中断,这样单片机的各种硬件中断就可以进行响应了。这段代码执行以后,使用鸿蒙系统的中断创建函数创建外部中断。
我们先不看外部中断内部是怎么实现的,先看一下这个中断创建函数是怎么工作的。在STM32中,中断函数能够被执行,是因为中断函数的地址或者叫做向量被放在中断向量表这个地方。当有外部中断请求发生的时候,单片机的硬件电路就会自动寻址到相应的中断函数,进而进入到函数里面去执行相应的代码。当然这中间肯定伴随着各种环境参数的保存,环境参数的保存,主要是为了解决从中断中恢复的时候,程序找到回去的路。
鸿蒙系统的中断创建函数,所做的主要事情,如下图所示,就是把一个数组g_hwiForm里面的数值初始化了。
这个数组里面的每一个数值存放了相应中断函数的地址以及相关的参数值。我们可以暂且认为这个数组存放的就是中断向量表,那这些个函数是怎么执行起来的,或者说是如何被调用的呢?
我们看一下,我们这款单片机的中断执行机制。RISC-V单片机中断向量表的起始地址,是由CSR寄存器mtvt来指定的,具体说明,如下图。那也就是说当有外部中断触发的时候,单片机硬件查询的首先是这个寄存器的地址,然后执行这个寄存器中的地址所指向的代码。那么我们的鸿蒙系统中,有没有对这个寄存器进行初始化呢?
大家可以看一下,实际上在操作系统启动的汇编代码部分,这个向量是被初始化了的。如下图,操作系统把TrapVector函数地址放入了t0,然后把t0放入了mtvec这个寄存器中。那TrapVector到底是什么呢?
大家看一看,这个TrapVector函数里面,在经过一系列的寄存器操作以后,调用了OsHwiInterruptDone和TaskSwitch这两个函数。这也就是说每次中断请求发生以后,都会执行这两个函数。
这个OsHwiInterruptDone函数地址里面,是不是就调用了我们初始化的中断函数呀。它根据不同的中断号码执行不同的中断函数,如下图所示。
在本篇文章刚开始的时候,我们是不是提到的外部中断响应函数OsMachineExternalInterrupt,如果有外部中断发出请求的话,就会进入到这个函数中去。
我们今天继续RISC-V I2C接口的介绍。上篇文章,我们大体比较了新思科技的I2C接口与STM32F030XX的I2C接口之间宏观上的区别。整体上,我们可以感觉新思科技的I2C接口使用起来相对来说比较麻烦。好在新思科技给出了最初版本的驱动程序设计,我们可以在他们的基础之上进行适当的改动,就可以把I2C通信的功能建立起来,同时在使用中可以加深对这些接口模块的理解。
上图的代码是程序中对I2C接口的初始化部分,和STM32的寄存器配置基本是一样的。主要是对寄存器的配置,通过在寄存器那里设定给定的值以后,I2C模块就可以按照指定的方式进行工作。
我们先从架构上来分析一下,首先代码中的reg_i2c这个变量,是I2C相关寄存器的基地址。红色字体寄存器的名字其实表示的是相关寄存器的偏移地址,这里也是采用“基地址+偏移地址”的方式进行寻址的。
上图中红框部分的描述,应该比较容易理解,相应的位配置好以后,写到DW_IC_CON(控制寄存器)里面去,就可以实现相应的功能了,比如选择FAST_SPEED模式、MASTER模式以及进行RESTART等等。
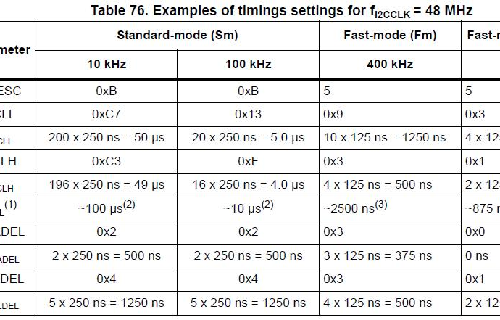
大家可以看一下,对于不同的速率,I2C接口模块会配置不同的时钟信号值。从数据上就能够看出来Slow模式和Fast模式,单周期内占用的时钟个数是不一致的,SLOW模式使用的时钟个数更多,不管是HCNT(high counter)还是LCNT(low counter)。这样的配置也是相对来说容易理解的,信号传递的速度越高,时钟频率肯定就会越大,那么时钟的HIGH和LOW部分肯定占据了更少的时间。从寄存器上来看,对于低速(SS)、快速(FS)和高速(HS)配置的时候,使用的是不同的寄存器,而不是在同样的寄存器中使用不同的位来配置。
上面两个函数是计算时钟的公式,具体这些计算方法和参数的设置应该是新思科技结合自己的硬件特性给出的。我们不要过于深究。
相比之下,STM32F030xx这款芯片中,对于时钟的配置就要简单的多。Reference Mannual中,对于不同的速率,只需要在SCL和SDA中配置相应的值就可以了,而且系统给出了推荐值,是不是简化了不少?不过它这样的表述,从另一方面来看,也掩盖了许多硬件实现的细节。这些细节,对于我们从硬件层面上更加深刻的去理解I2C协议,肯定比较有帮助。只不过我们实际使用的过程中,一般不需要了解得这么细致。当然,从本质上讲,两者实现的思路肯定是一样的。
时钟信号配置完以后,下一步就是要对SDA和中断系统进行配置了。
大家可以看一下,IC_SDA_HOLD这个位的解释,就是SCL由高到低变化后,SDA这个位还需要保持多少时间。我们说I2C的协议里面是不是定义了,在SCL为高的时候,SDA的数据信号是不是不能变化的呀。怎么能够实现不能变化呢?是不是就是要把SDA的信号延时一部分时间再变化,是不是就可以了呀。这个寄存器就是实现这个功能的。
最后一个是关于SPKLEN的,这个是一个保护设计,为了防止电压或者电流冲击对信号造成影响的。我们按照默认的配置写就可以了。
今天关于I2C初始化部分介绍,我们就先到这里。后续的内容,我们会在文章中持续更新。
 张角
张角