电源
91篇文章
大家好,我是张飞实战电子黄忠老师,今天分享如何通过手册理解单片机IO知识点。
含义解释:
1. GPIO:同我们常说的IO口一样, General Purpose Input Output (通用输入/输出)简称为GPIO,每个GPIO端口可通过软件分别配置成输入或输出模式。
2. 外设:指的是除CPU以外的外围功能模块,只不过这部分电路依旧被封装在单片机内部,比如IO,ADC,DAC,TIM等。
3. 复位:把MCU恢复到最开始的状态,比如说我们把电脑重启了一次,就相当于复位了一次,在这里我们把MCU恢复到初始的状态称为复位。
4. 往某一位写1,在硬件上就相当于把把它设置成高电平,清0则与之相反。
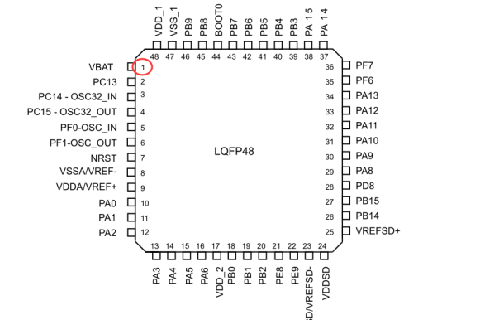
芯片的缩略封装图:
STM32F373CCT6 总共有48个引脚(图中左上角红色圈起来的1代表芯片的1号引脚,后面的以此类推,我们这里把1脚简称1Pin),分以下几个类别:
1.可以编程控制的引脚:PAx(x表示0,1,2…),PBx(x表示0,1,2…)等以相同类似方式命名的。STM32F373CCT6分多组 IO口,分别用大写字母表示,即
x=A/B/C/D/E/F,例如GPIOA,表示A组IO口,这组IO口下面又有很多引脚,那么我们就用PA0,PA1,PA2等方式来表示,每组下面最多16个IO口。通俗点来讲:GPIOA就相当于八年级五班这个班级,PA0,PA1相当于班里的学生,有叫李刚的,有叫张华的等等,每个班最多16个学生。
我们看到有的可编程控制的引脚,例如PC14-OSC32-IN,那么说明这个引脚有多种功能,可以当IO口用,也可以当做OSC32-IN用,在下面我们会具体解释这样的引脚。
2. 不可编程控制的引脚:1Pin(备用电源正脚),7 Pin(复位脚), 8 Pin(模拟电源负脚), 9 Pin(模拟电源/参考电压正脚), 17 Pin(数字电源正脚),23 Pin(SDADC1, SDADC2, SDADC3 地),24 Pin(SDADC1, SDADC2, SDADC3 电源),25 Pin(SDADC1, SDADC2, SDADC3的外部参考电压正),44 Pin(启动内存选择引脚),47 Pin(数字电源负脚),48 Pin(数字电源正脚)。
1. 后备区域供电脚 VBAT 脚的供电采用 CR1220 纽扣电池和 VCC3.3 混合供电的方式,在有外部电源 (VCC3.3) 的时候, CR1220 不给 VBAT 供电, 而在外部电源断开的时候, 则由 CR1220给其供电。这样,VBAT 总是有电的,以保证 RTC 的走时以及后备寄存器的内容不丢失。
2. BOOT0
关于详细的引脚功能定义可以查阅《STM32F373xx》数据手册第33页,这里我们解释下关于引脚的功能问题:
1. 默认功能:也就是引脚的普通功能。
2. 复用功能:即将IO口用作普通输入输出以外的功能,通过配置相关寄存器后选择的功能,例如串口输入输出,使用时需要配置复用模式。
想要配置成复用功能,首先需要查看引脚定义看看这个IO口可不可以被配成复用功能,这个是由IO的内部电路决定的。如果有才可以被配置,配置成复用功能不仅仅是要通过寄存器GPIOx_MODER配制成复用功能模式,而且还要通过GPIOx_AFRL,GPIOx_AFRH寄存器选择IO复用功能。这样IO口才能真正被配成复用功能。
3. 附加功能:配置相关外设寄存器来选择的功能,比方配置ADC使能某些通道等来使能相应管脚的附加功能。同样想要配置成附加功能,首先需要查看引脚定义看看这个IO口可不可以被配成附加功能,这个也是由IO的内部电路决定的。如果有,那么通过寄存器GPIOx_MODER配制成模拟功能模式。
每组通用 I/O 端口包括 4 个 32 位配置寄存器 (MODER、 OTYPER、 OSPEEDR和 PUPDR) 、2 个 32 位数据寄存器(IDR 和 ODR) 、1 个 32 位置位/复位寄存器 (BSRR)、1 个 32 位锁定寄存器 (LCKR) 和 2 个 32 位复用功能选择寄存器(AFRH 和 AFRL)等,可以被配置成一下几种不同的模式:
输入上拉:IO口上拉就是在IO口通过接一个电阻到电源(注意这个电压要和单片机供电电压相同,否则过高会烧毁IO),电阻的大小决定了电源到IO口电流的不同,这就是我们常说的弱上拉等。下面附图一张。
输入下拉:下拉就是在IO口通过接一个电阻到地,电阻的大小决定了IO口到地电流的不同,这就是我们常说的弱下拉等。下面附图一张。
输入浮空/模拟输入:浮空(floating)就是逻辑器件的输入引脚即不接高电平,也不接低电平。浮空最大的特点就是电压的不确定性,它可能是0V,也可能是VCC,还可能是介于两者之间的某个值. 浮空一般用来做ADC输入用,可能有的芯片把浮空模式和模拟输入模式分开了,在此解释一下,在浮空模式下使能了IO的模拟功能就相当于是模拟输入。
开漏输出:开漏输出就是我们所说的OC输出,不输出电压,相当于N型三极管的集电极作为单片机的IO口,需要在外部加一个上拉电阻配合使用。如图:
推挽输出:可以输出高,低电平,但相对于普通的输出而言,这种输出方式增加了输出能力。如图:
复用开漏输出、复用推挽输出:可以理解为GPIO口被用作第二功能时的配置情况(即并非作为通用IO口使用)。
上图为引脚的内部电路框图(红圈内或旁边数字代表序号,下面简称1号等)
输出部分解析:输出分三路
第一路,1号(读/写动作-由片内外设控制)——>3号(经过一个逻辑门->输出控制电路)
第二路,15号(写动作)——>14号(Bit Set/Reset register 位设置/清零寄存器),——>13号(Output data register数据输出寄存器)——>3号(经过一个逻辑门->输出控制电路)
第三路,2号(复用功能输出)——>3号(经过一个逻辑门->输出控制电路)。
三路都通过控制4号(MOS管电路,根据配置的不同模式,驱动P-MOS或者N-MOS或者两个一起驱动)——>5/7号的下拉/上拉电阻(我们可以看到上/下拉电阻有开关控制,意思就是可以通过外部的某些东西去控制使能或者失能上/下拉)——>6号的保护二极管(这里利用了二极管钳位的功能,可以在一部分程度上起到保护引脚的作用)——>IO口。
输入操作解析:同样分三路
第一路,IO口——>6号的保护二极管输出到——>9号(模拟输入)——> 片上外设
第二路,IO口——>6号的保护二极管输出到——>8号(开关,可靠外部控制)——>10号(复用功能输入)——> 片上外设
第三路,IO口——>6号的保护二极管输出到——>8号(开关,可靠外部控制)——>12号(Input data register输入数据寄存器)——> 11号(可供读取数据)。
如何结合寄存器以及硬件电路来实现具体输入输出请看下篇分析~

由于在嵌入式系统中必须考虑程序规模的问题,因此,对程序中的变量的初始化也需要进行慎重的考虑。在C语言中,基本数据结构(字符型、整型)的初始化相对简单;数组、结构体属于C语言中的构造类型,其变量在初始化的时候相对复杂,也有一些比较特殊的技巧和方法。
数组的初始化
以下的代码是一个关于数组的初始化的示例:
从程序上来看,方式1直接使用数组初始化的方式,方式2使用了函数完成数组的赋值。方式3是方式2的等价形式。
从表面上来看方式1要简单很多,实际上,无论从代码的规模上,还是效率上,二者都没有太大区别。
方式1看似直接使用初始化的过程完成赋值,实际上对于类似char a[10]=”abcde”形式的语句,编译器还是需要做很多事情才能完成。a是函数中使用局部数组变量,开辟在栈内存空间上。当程序运行至fun处,不会凭空得到一段字符串,也就是说”abcde”必须有地方存放,这就是只读区(RO Data)。因此,程序运行赋值语句时,要在栈上开辟10个字节的空间,然后将调用内存复制函数将只读区的”abcde”复制到这个栈空间上。
由此可见,方式1和方式2的运行没有本质区别,只是方式1利用编译器完成的操作,方式2要在运行程序时完成,二者依赖的库不同,但是都是内存复制一类的功能,同时二者的”abcde”都需要占用只读数据区的空间。
从占用空间和运行效率上,方式1,方式2,方式3基本都是等价的。无论程序中有没有声明,”abcde”所占用的只读数据区(RO Data)都是必需的,复制的过程也是必需的。
方式4是直接把a定义为已初始化可读写的全局变量,在使用的时候直接操作。作为已初始化的全局变量(RW Data),将在程序总体初始化的阶段复制到内存中,而不是在函数调用的时候复制。其优点是不用在函数调用的时候完成内存复制操作,缺点是全局的数据会一直占用内存,而栈上数据将在函数退出的时候释放。
实质上,在数组的定义中,变量可以是全局变量或者局部变量,如果是全局变量,将会增加10字节已初始化的数据区(RW Data),初始化的内容将被放入,这段数据区是可读写的,对全局变量的访问就是对这段已初始化的数据区的访问。如果是局部变量,内容被放入只读数据区,函数运行到的时候要在栈上分配相应的数据区,把只读区的内容复制到栈上,对数组的访问是访问这段在栈上的内存。
结构体的初始化
在数组初始化的时候可以使用直接赋值的方式,而在结构体初始化的时候可以使用参数列表。这两种形式比较类似,因此结构体在初始化阶段和数组的情况是相似的。
例如:
结构体的两种初始化方式和上面数组的两种初始化方式有一定的对应关系。第一种方式使用成员列表的方式初始化,第二种使用对结构体成员变量赋值的方式。实质上,第1种方式编译器将自动生成一些指令完成变量a的初始化,而第2种方式编译器在处理Score a语句的时候只需要开辟栈空间,而在后面在对其每个成员进行赋值,开辟栈空间和赋值都是简单的处理语句,编译器没有做过多的工作。
在嵌入式系统中,对程序性能是非常敏感的,有以下几个方面的开销:首先是程序各段执行的效率,这是程序开销的主要方面,其次是函数的参数和返回值传递中入栈和出栈的时间。由于各个处理器一般都具有直接栈操作的指令(入栈和出栈),因此函数中使用的局部变量的可以使用处理器的基本的入栈和出栈指令来完成,这种指令的执行性能是很高的。但如果是为变量赋初值,虽然是C语言中基本的语法,却并不能以简单的方式处理,编译器实际上需要做一些附加的工作,来完成对局部变量的初始化。也就是说在程序中没有写出的语句,编译器也需要处理。根据以上的程序和分析,可见如果栈上变量需要初始化,有可能也会带来一定的开销。

大家好,我是张飞实战电子黄忠老师;前面文章分享了I2C的一个标准规范,只是知道这些标准规范,还不能和目标器件进行正常通信,我们以24C02(EEPROM)为例来做一个简单说明,想要和EEPROM通信,就得遵从EEPROM的通信规范,因为EEPROM是一个不可编程器件,它的规范是固定的。
那么它都有哪些规范需要我们去注意呢?比如数据传输的时候拉高拉低要保持多长时间才有效、通信的时候要按照什么格式写,先发高位还是低位等等。在这里一共有4个时间需要注意,分别为数据建立时间,保持时间,时钟高电平时间,时钟低电平时间,手册上对这几个时间都是有要求的。
从图中我们看出,当我们在SCL为低电平期间,把SDA数据改变,这个时候SCL时钟还是要保持一段时间才能拉高发送,这个保持的时间就是数据建立时间。
图1 图2
从图1中箭头处可以看出,当我们把SCL拉低之后,SDA数据是不可以立马去改变的,SCL时钟拉低还是要保持一段时间才能去改变SDA数据线电平的,这个时间就是保持时间。
从图2中箭头处可以看出,当我们把SCL拉高发送数据的时候,这个SCL时钟保持高电平,是要持续一定时间的,这个时间就是时钟高电平时间,时钟低电平时间也是同理。
这个是24C02器件在400K高速通信4个时间的要求,那我们在进行单片机编程的时候,我们需要根据这几个C间设置相关寄存器,在24C02操作时,不光有这几个时间,它还有自己的通信协议规范。我们以字节写为例,来进行说明。
下图就是24C02通信协议,我们先看对24C02写数据,是1个字节写指令,根据这个写一个字节对应的定义我们来一个一个进行解释。
1表示启动
2表示设备地址也就是我们说的从机地址(设备地址为7位),发地址时,先发地址的高位,再发低位(MSB为高位,MSB在前,表示先发),可以通过24C02器件某几个特定的引脚接不动的电平状态来设置地址。
3表示是对从机如何操作,是读还是写(一个位),这里是写操作。
4表示要读写数据的地址
5表示要读写的数据内容
6表示停止
7表示每进行一次传输从机的应答,每次传送1个字节,也就是8个bit,也就是每8个bit一个ACK信号
以上就是一个字节的写,当然还有多字节写,单字节读,多字节读等操作,原理都是一样的,知道了这些之后,我们才可以对应的去写程序代码。赶快去试试吧!
大家好,我是张飞实战电子的黄忠老师,今天我们来讲解在嵌入式系统中大小端和对齐端的问题
C语言是一种高级语言,在大多数情况下C语言的代码是和具体的处理器体系结构无关的。然而,在嵌入式系统的编程中,有可能涉及对内存的具体操作。在大小端和内存对齐问题上,C语言就不能屏蔽不同体系结构处理器的差别,也就是说同样的C语言代码在不同的体系结构的处理器上,有可能产生不同的结果。
大小端问题又叫字节序的问题。在各种体系结构的处理器中,对多字节数据的内存操作有着不同的定义。处理器对内存数据的操作有读写两种,这就涉及处理器在读写一个多字节的内存的时候,高字节是在内存的高地址还是低地址。一般在32位或者16位的处理器中,都具有将32位数据和16位数据读写到内存中的指令,这时不同的大小端模式将有不同的结果。
如果读写指令针对的数据长度和类型是一致的,无论数据在内存中存放的形式如何,处理器整体读写都没有问题。这种整内存协调的读写操作问题,一般不会涉及处理器的大小端。
当处理器读写指令针对的数据长度不一致的时候就会涉及大小端的问题,例如:
将0x76543210整体放入内存,然后在内存的首地址用单字节读取的命令读出。
如果不知道大小端模式的情况下,读取的值是多少你能确定吗?
这时就涉及处理器是大端还是小端的问题。
对于小端处理器,写内存的时候会将内存低地址处放入源数据的低字节,在内存的高地址处放入源数据的高字节;读内存的时候,将内存中低地址的数据就视为目标数据的低字节,对应的高地址数据是目标数据的高字节。
对于大端处理器,跟小端就相反的。内存低地址存放数据的高字节,高地址存放数据的低字节。
例如:数据0x76543210在内存中的大端或小端的存放形式如下:
上面的示例只是处理器自身读取和写入内存的情况,在更多的情况下,内存中的数据可能来自外界的输入,例如:来自网络的数据包;处理器在写内存的时候,这块内存也可能是给系统中别的设备使用的,例如:处理器写显示内存的情况。这时,就更需要注意处理器的大小端问题,只有大小端处理协调匹配,才能获得正确的结果。
在C语言中,使用指针就可以操作内存,指针的基本类型long和short分别代表了32位和16位的数据。使用16位或32位指针操作内存的时候,同样涉及内存的大小端问题。
上面我们说了一下内存读写的模式不同,一个地址存的数据不同。
接下来我们说一下内存对齐的问题,有人会说了内存对齐不对齐还需要你来管吗?这个在写程序的时候也是有讲究的,那么到底什么是内存对齐?为什么要有这个概念呢,我们来一起学习一下吧。
内存对齐操作的含义是:对于一个4字节的数据,要求其内存是4字节对齐的(地址为4字节的整数倍)。32位对齐的含义是其内存的地址的最低位是:0x0,0x4,0x8,0xC
16位对齐的含义是其内存的地址的最低位是:0x0,0x2,0x4,0x6,0x8,0xA,0xC,0xE
显然,对于单字节的内存读写操作,没有内存对齐的问题。从处理器硬件的角度,处理器更适合处理对齐的内存操作。对于非对齐的内存操作,不同的处理器则有不同的结果。
局部变量建立在栈空间上的,由编译器分配,一般保证它们都是对齐的。但是在程序中可能出现不对齐的内存操作。对于嵌入式系统中常用的ARM体系结构,并不支持不对齐的地址操作,当进行不对齐的地址访问的时候,处理器将引发异常。
在嵌入式程序的编写过程中,更需要注意内存对齐的问题。对于内存操作,使用字节操作(8bit)不会有内存对齐的问题,但是效率比较低。在32位系统中,应该尽量使用32位的数据操作,但这将带来内存对齐的问题,因此需要根据系统的具体情况选择合适的内存操作。
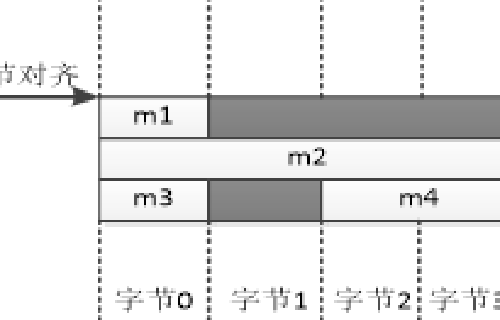
我们再来说说常纠结或者容易迷惑的结构体成员的对齐问题。
结构体是一个基本的语法单元。在32位系统中,编译器一般会对结构体的成员变量作一定的对齐处理。例如,在程序中定义如下结构体:
typedef struct _S1
{
char m1;
int m2;
char m3;
short m4;
}S1;
在结构体的定义上,结构体的大小应该是各个结构体成员的大小之和。但是,对于上面这个结构体S1,它的大小并不等于4个成员变量之和。在这种定义中,三个成员变量之和是1+4+2+2=8,但是结构体的大小并不是8字节。
编译器在处理结构体的时候,默认将结构体内部各个变量的内存都是对齐的,由此在结构体的内部可能出现一些空的字节。
一般情况下,在结构体含有4字节长整型成员的时候,结构体的大小将是4字节的倍数。为了对齐可能需要在结构体的最后补充1~3个字节。
如果结构体中含有2字节短整型成员的时候,结构体的大小将是2字节的倍数。为了对齐可能需要在结构体的最后补充一个字节。
这个算字节数的一般出现在找工作中的笔试题的概率还是很高的,其实就是考察的对这个内存对齐的掌握。

Cortex-Mx启动流程步骤详解
单片机在上电的时候会经历一个启动的流程,不管是你从手册描述上看得见的,还是看不见的,亦或者你不知道还有这种操作的,这个启动都是客观事实存在的,今天我们就用白话文来唠一唠Cortex-Mx系列的启动流程(此文章知识广泛适用于CPU为Cortex-Mx系列的MCU)。
图1
如上图为STM32F0系列单片机系统存储器的映射图(其他系列型号,映射图会有区别,但流程还是一样的),通常,当处理器从复位中启动时,它首先会访问位于0x0000 0000地址处的向量表,这个向量表是什么?从哪里来?跟程序员又有什么关系?明确的讲这几个问题跟我们的启动文件是紧密相关的。启动文件就是对启动流程的“展现”,启动文件中包含了向量表(向量表中包含了堆栈指针地址、复位向量程序地址、以及系统中各类中断函数的入口地址,简单点讲就是单片机启动的时候得经过这个向量表,执行复位程序得经过这个向量表,执行中断还得经过向量表,从向量表中找中断函数的入口地址)。当然启动文件也是由程序员写的(只不过大多数由厂家的Coder代劳了)。下面我们一起来弄清楚吧!
图2(VectorTable部分截图)
上图为厂家参考手册上给出的向量表的部分截图,启动文件中程序员编写的向量表就是根据这个表格来编写的,每一行为向量表的一个组成成员,第一行为表示堆栈指针初始值,第二个字为复位向量地址,后面的行是各种类型的中断向量地址,也就是中断函数的入口地址(在图中第一个字被描述为保留,第二个字描述为复位,这两行内容非常重要!)。
前面我们说了一个关键点,当处理器从复位中启动时,它首先会访问0x0000 0000地址处的向量表,并读取向量表的前2个字,第一个字为堆栈指针MSP初始值(堆栈是一个临时的空间,用来临时存储一些信息,就像电影里面的“龙门客栈”一样,供过往客人临时歇脚。);第二个字为复位向量,它表示程序执行的起始地址。当读取到该地址之后,会自动跳到复位向量处开始执行程序(图2红框处,最右边的一列地址栏,第一行地址空间从0x0000 0000开始 - 0x0000 0003结束,第二行从0x0000 0004开始-0x0000 0007结束,后面以此类推,每行占4个字节,即1个字)。
但是比较晕的是:图1中大家可以看到,地址0x0000 0000处已经存在内容了,是系统BOOT的配置,这段内容是厂家固化的一段代码,我们写的代码是存储在从0x0800 0000开始往后的地方,即Main Flash Memory存储区(见图1)。
那大家想我们写的代码(启动文件也算写的代码的一部分),是放在FLASH存储区的,而单片机上电的时候是从0x0000 0000处开始执行,那么系统是怎么访问到我们自己写的这个向量表呢?
这个设计者考虑了,系统会自动把我们代码启动文件中的向量表映射到0x0000 0000地址处,也就是说在0x0800 0000开始存放代码的地方我们有一张自己写的向量表,系统会找到这张向量表,把这张向量表映射到0x0000 0000处,这样就相当于在0x0000 0000开始的这个地方也有了一张向量表了。
图3
如图3,系统一旦读取到向量表的第二个字复位向量的地址时,那么就跳到复位向量的地址开始执行程序,我们可以在复位向量地址处写上自己的用户代码,执行完这段代码之后,指挥程序跳到主函数main程序运行,那么这样连贯起来,程序正常跑起来了,这就是一个完整的启动。
 黄忠
黄忠