电源
91篇文章
大家好,我是张飞实战电子张角老师!
在单片机开发过程中,我们常用的通信协议主要有UART,SPI,I2C这几种,是吧。这三种通信协议,本质上都是串口通信,也就是说在一个时钟周期中,只发送一个数据位。顾名思义,如果在一个时钟周期里面发送多个数据,是不是就是并行通信了,并行通信,自然需要更多的数据线,进而会占据更多的资源。不过并行通信的好处也是显而易见的,也就是说单位时间内(或者说一个时钟周期内)可以传递更多的数据,比如在大屏显示这种通信类型的时候,一般就需要使用并行传输协议。没办法呀,数据量太大,不得不如此。但是在相对低速的通信场景中,串口通信能够满足绝大多数的需求,所以在单片机的外设资源中,串口通信占据了不少份额。
我们首先来分析一下串口通信的原理。串口通信的接收过程,大概就是上图中描述的样子。这个图中我们只是使用三个数据来示意表达。DSR发送过来的“010”这三个数被移位寄存器移位以后,通过“D1,D2,D3”并行输出。实际上一般这里是8个D触发器,实现8个串行数据的并出效果,单片机的最小存储单元一般是8个bits么。发送端实现的一般是“并入串出”,只是方向反过来了,原理和上面的一样的。上图中N管和P管组成的电路是为了上电的时候,对D触发器的数据进行复位,这个地方大家不必太在意。
在UART、SPI和I2C这三种最为常用的串口通信中,以UART的实现最为简单,通信的双方不需要严格的时钟配合,只需要设定好波特率就可以了。所谓不需要严格的时钟同步,也就是说通信的双方可以使用各自的时钟,通信双方的时钟频率不一定相等,我们在使用UART进行数据通信的时候,每次发送的数据最长是8个bits,可以比这个短,但是不能再比这个长了。如下图所示,数据位可以是8/7/6三类。那究竟是为什么呢?一次发送多个数据不行么?
异步通信可以允许通信的双方具有一定的时钟误差,时钟误差越大,每次能够发送的数据位数就越短;时钟误差越小,每次能够发送的数据长度也就越长。为什么是这样呢?假定对于主机,一个bit对应的脉冲数正好是10个,对于从机一个bit对应的脉冲数是10.2个。那么随着bit数的增多,比如达到5个bit的时候,从机就会出现有51个脉冲数,那多出来的一个脉冲数该怎么对应呢?电路设计上该怎么设计呢?换句话说,就会出现数据错位。从这个例子来看,只要从机和主机时间频率上有误差,随着单次数据传递量的增长,那么一定会有数据错位出现。这个也就是UART进行数据传输的时候,一次只传输一个byte,主要的目的就是为了防止出现数据错乱的情况发生。
我们下面用图形化的方式来说明一下这个问题。
如上图所示,PWM1和PWM2是两个不同的时钟信号,大家可以看一下这两个时钟的周期明显是不一样的。我们让这两个时钟都同时从A时刻起步,大家可以看一下,到达B时刻的时候PWM1和PWM2已经反相了,到达C时刻的时候PWM1和PWM2又变成同相了。大家可以看一下,到达C时刻的时候,PWM2的周期数已经比PWM1多了一个了,那么多出来的这个时钟周期就会出现无法和数据位匹配的情况。反过来对于数据来说,也就是会出现数据错乱的现象。
但是SPI和UART通信的双方有一条时钟线相连,通过这条时钟线他们实现了严格的时序匹配。因为双方时序完全一致,那么在数据采样、移位以及存储的时候,就不可能出现数据错乱的情况。某种意义上时钟有多快,数据传输的速度就会有多快。当然实际应用中,SPI和I2C数据传输的速度,还受到通信接口本身器件特性(结电容)、CPU处理数据的速度、存储器存储数据的速度以及布线等因素的影响,具体的数据传输速度是考虑了诸多因素之后确定的一个值,我们需要具体应用具体分析。
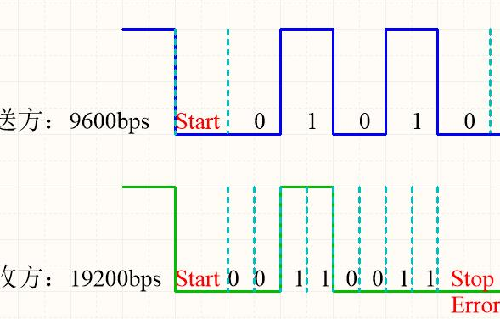
对于Uart来说,为什么通信双方的波特率需要设置的是一样的呢?波特率是不是就是数字信号采样的速率,如果通信双方采样的速率不一样,很显然会导致错误的结果。我们假定UART发送方的波特率是9600,接收方的波特率是19200。发送方发送的数据是“0101 0001”,那接收方会接收到什么数据呢?我们这里接收方数据采样的速率是不是发送方的两倍呀,大家可以看下面的图。
接收方数据采样出来的数据是不是“0011 0011”呀,是不是发送方的每个数据才接收方采样了两次呀,而且停止位是不是还出现了错误。这个例子从侧面说明了,发送方和接收方波特率必须一致的原因。
异步通信,相比同步通信,还有一个缺点,那就是说信号传递的速度相对较慢。在UART协议中,每个字符都需要起始位和停止位作为字符和开始和结束的标志,另外还有一个校验位,这些辅助设施大约增加了20%的信息位,以至占用了信号传输的时间,所以通信的速度就上不去。
对UART通信过程的探讨,我们先到这里。
大家好,我是张飞实战电子张角老师!
同学们好,我们从今天开始探讨单片机C语言,我们首先从if和for等基本语句结构开始。
if和for,这两个从本质上来说,是不是C语言的两个关键字呀。那么我们为什么又把它称之为C语言的基本结构的一部分呢。要回答这个问题,我们是不是首先要搞清楚C语言的基本结构是什么?
实际上,任何结构化编程语言的基本结构都是相同的,也就是三种基本的程序结构:顺序,分支和循环。由这三者最基本的结构,可以搭建出任何我们想实现的程序结构。在狄杰斯特拉(Edsger W. Dijkstra)反复研究面条式代码(spaghetti code),并在1968年给某位编辑写了一篇著名的简信,题为《Go to语句是有害的》之后,计算机科学家Corrado Bohm和Giuseppe Jacopini证明,使用顺序(sequencing),分支/选择(alternation)和循环(iteration)这三种流程结构就足以表达所有程序的本质。C语言作为结构化编程语言的一种,其程序结构,自然也是由这三种最基本的程序结构组成。
顺序执行程序,这个很好理解,一条语句接着一条语句执行就可以了。那么C语言的分支和循环是如何实现的呢?
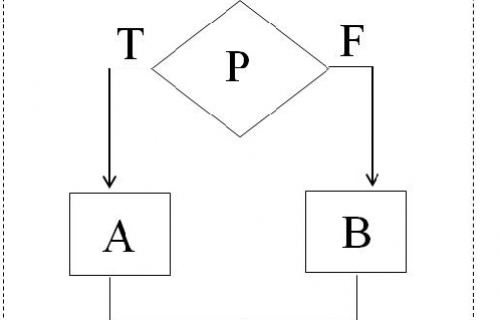
对于分支,我们常见的关键词是不是有if/else和switch/case两种组合呀。if/else翻译过来,是不是就是“如果…,否则…”,是一个条件判断。如果用伪代码的方式来进行表达的话,一般有这两种形式。
第一种形式如下:
if(条件为真)
{
代码段1;
}
else
{
代码段2;
}
这里else的含义其实就是条件不为真,那么也就是条件为假。
第二种形式是这样的,
if(条件1为真)
{
代码段1;
}
else if(条件2为真)
{
代码段2;
}
else
{
代码段3;
}
第一种形式和第二种形式本质上的区别,其实就是第一个是双分支,第二个是多分支。两种不同的分支,我们要根据具体情况去使用。某种意义上多分支模式可以由双分支演变而来,比如我们可以在双分支模式里面的else里嵌套一个双分支结构就可以了。
if(条件1为真)
{
代码段1;
}
else
{
if(条件2为真)
{
代码段2;
}
else
{
代码段3;
}
}
从这个意义上看,双分支和多分支其实是一回事情,本质上都是分支。分支这个概念,大家应该都是相对容易接受的,任何一件事情总有它的对立面,高对低,胖对瘦,大对小,物质对暗物质等等。分支这个概念应该是反映了事物的一种本源的状态,是描述程序是不可再进行切分的维度,也就是说分支成为了任何程序的三种基本结构之一。
其实对于多分支的情况,C语言有另外一套关键字组合switch/case,写成伪代码的形式,大概是这样的。
switch(变量){
case 常数1:
代码段1;
break;
case 常数2:
代码段2;
break;
case 常数3:
代码段3;
break;
。。。
default:
代码段n;
break;
}
大家注意没,对于switch/case组合来说,它的条件一定要是常量,而且要是整数。这个是不是对判断的条件作出了限制呀。这里的default关键字,是和if/else里面的else对应的,表示意外情况。从表面看,switch/case适用于逻辑条件简单,但是分类较多的情况;if/else适用于判断条件复杂,但是分支较少的情况。但是从另外一个层面看来,switch/case所具备的功能,if/else完成起来,完全没有问题呀。那为什么还要搞出来这一个关键字组合呢?
我个人的理解是switch/case关键字的执行效率,在某些情况下,要比if/else要高。
int a = 0;
switch(a)
{
case -1:
break;
case -2:
break;
case -3:
break;
case -4:
break;
case 0:
printf("I am in switch case!n");
break;
default:
break;
}
printf("I am between the switch case and if/else if/else!n");
if (-1 == a)
{
}
else if (-2 == a)
{
}
else if (-3 == a)
{
}
else if (-4 == a)
{
}
else if (-5 == a)
{
}
else
{
printf("I am in if/else if/else!n");
}
比如对于上面的代码段,对于switch/case关键词对来说,程序是直接跳到case为0的情况下的;但是对于if/else而言,程序则是一句一句比较之后才达到了“else”这一句,程序执行效率的高低是显而易见的。
但是我们说,switch/case的程序执行效率可以比较高,并不是没有条件的。从汇编语言的层面来看,switch/case是建立了一张跳转表,因此需要一定的空间才行。这里某种程度上有以空间换时间的意思。
因此,如果程序可以使用switch/case尽量使用这个,以便提高它的执行效率。其实,我们这样比对一番之后,自己也就轻而易举地牢牢记住了它们,这个可能也就是知其然知其所以然的效果,符合人的记忆规律。
讲完了分支,我们来看一下循环。循环这个基本结构,在C语言里面,一共有两种实现方式,for循环和while循环,其中while循环还可以分为两种,一种是while循环,一种是do/while循环。我们下面分别看一下,这三种结构的程序表达大概是什么模样。
for(循环控制变量初始化;循环终止条件;循环控制变量增量){
循环体;
}
for循环的执行步骤是:首先执行循环变量的初始化,然后执行循环终止条件;如果判断条件为假(不符合终止条件),那么就开始执行循环体;然后执行循环控制变量的增量程序,执行完以后,再去判断是不是符合循环终止条件;如何符合条件,那么就退出循环;如果不符合条件,那么就继续执行循环体,并重复执行上述步骤。
感觉用第二种方式来描述这个循环体的执行过程,更为清晰。第一,先进行循环控制变量初始化;第二,执行循环终止条件,如果判断结果为假,则进入第三步;如果为假则循环终止并退出;第三,执行循环体;第四,执行循环控制变量增量,转入第二步;
注意,其实for循环括号中的三部分其实都可以省略,如果全部省略了,就变成了一个无限循环的死循环,跳不出来了。无限循环在操作系统中使用的是非常多的,每一个任务都是一个无限循环体,包括main函数也是一个无限循环体。
下面,我们来看一下while循环的代码格式。
循环控制变量初始化;
while(循环终止条件){
循环体;
循环控制变量增量;
}
while循环的执行步骤可以描述为如下的样子。
第一在while之前,先执行循环控制变量的初始化;第二,判断循环终止条件是否成立,如果成立那么就跳出循环,如果不成立就进入第三步;第三步,执行循环体;第四步,执行循环控制变量增量,然后进入第二步。
do/while的代码格式是什么样子呢?
循环控制变量初始化;
do{
循环体;
循环控制变量增量;
}while(循环终止条件)
while循环的执行步骤可以描述为如下的样子。第一,在do(也就是执行)之前,先执行循环控制变量的初始化;第二,先执行一次循环体和循环控制变量的增量;第三步,判断循环终止条件是否成立,如果成立那么就跳出循环,如果不成立就进入第二步;
我们来看一下呀,while和do/while主要的区别,一个是先判断再执行,一个是先执行再判断,那么也就是说do/while这个关键字组合中,函数体至少执行一次。但是这并不影响while和do/while之间的转化呀,同样的功能绝大多数情况下,可以用while也可以使用do/while来实现。那么有没有必须要用do/while的时候呢?答案是有的,在linux编程中,do/while常用的一个方式是do while(0)。
比如,我需要定义一个宏:
#define SAFE_FREE(p) do{free(p); p=NULL} while(0)
假设这里去掉do{....} while(0),及定义为:
#define SAFE_FREE(p) free(p); p=NULL;
那么以下代码:
If(NULL!=p)
SAFE_FREE(p)
else
.......
会被展开成如下的有仇
If(NULL!=p)
free(p); p=NULL;
else
.......
展开之后,存在两个问题。因为if分支后面有两个语句,会导致else分支没有对应的if,编译失败。即使假设没有else分支,SAFE_FREE中的第二句,无论if测试是否通过,这个都会被执行。那么如何解决上述问题呢?有人说给SAFE_FREE的定义加上{}就可以了,比如如下的样子:
#define SAFE_FREE(p) { free(p); p=NULL; }
代码展开如下:
If(NULL!=p)
{ free(p); p=NULL; };
else
.......
这样问题又来了,else 没有对应的if了,编译还是会失败。但是使用了do while(0)则可以完美解决上述问题。代码展开如下,
If(NULL!=p)
do { free(p); p=NULL; } while(0);
else
.......
所以,do while(0)的使用是为了保证宏定义的使用者能无编译错误的使用宏。
下面我们讨论一下,为什么C语言有了for,还需要while呢?除了上面的do while(0)的必要性之外,好像还真得没有确切的其他原因。比如在golang编译其中,就只有for,没有while了;再比如,java的源代码里面,就是有一堆的for(;;),据说可以提高性能。所以更大程度上讲,C语言只是为了,兼容程序员的编码习惯,保留了while这个关键字而已。
一些更现代的语言还加入了foreach、for in这种专门遍历集合的语法糖,也有python、ruby这种直接抛弃了C语言三段式for,只保留了for in,而把非遍历型的循环统统放到while循环里面的做法。
我们这次关于程序基本结构的探讨就先到这里。
参考资料:
① 基础学习C语言第四章:三种基本结构 https://zhuanlan.zhihu.com/p/97629275
② Linux - switch/case与if/else if/else的效率比较
http://blog.sina.com.cn/s/blog_5acb430f0100ael9.html
https://www.cnblogs.com/anlia/p/11685639.html
④ 深度理解do{} while(0)
https://blog.csdn.net/weibo1230123/article/details/81904498

我们今天探讨C语言变量的定义和初始化。那么我们首先要明确三个问题。第一,我们要明白什么是变量,或者为什么C语言一定要有变量;第二个在C语言中如何去表达这些变量,或者说C语言都有什么类型的变量如何定义这些变量;第三,变量为什么要初始化,以及如何初始化。
第一个问题,关于变量,一个最通俗的理解就是变化的量。本来外在的物质世界就是在不断变化的,不是有句话么:“唯一不变的就是变化”。C语言作为描述客观世界变化的一种语言,首先就是要有能够对外界事物变化状态量化的工具,那么这个工具就是变量。数字世界,首先就是量化,这个是一切后续工作的基础。
我们下面拿几个常用的变量类型进行说明,比如char型变量,它主要是用来应对0 – 255之间变化的事物的,比如字符什么的。比如float,浮点型的变量,它主要是量化客观世界中模拟量的事物,比如汽车的速度、太阳光的强度等等;再比如int型的变量,它的描述范围就比char型大得多了,它主要是应对整数变化的客观事物的,比如学生的个数、苹果的个数等等。
那么实际上,我们说C语言的变量远不止这些简单的数据类型,是吧。我们还有数组,结构体,还有指针、栈、链表等等。每种数据类型的出现都是为了解决一个量化的问题,比如指针,它主要是定位量化计算机中内存寻址问题;比如结构体,它的定位主要是用来描述复杂事物的,就比如汽车,它不仅有行驶的速度,还有轮子的个数,椅子的个数等等;再比如栈,它的主要作用是解决任务切换以及函数调用时,程序现场的保护问题。
那么也就是说每一个变量类型或者量化工具类型的出现,都是有原因的,都是为了解决实际问题的。当我们从这个视角去看这些变量类型和必要性的时候,我们的理解就会深刻很多。举个例子,比如面向对象数据类型的产生,就是把方法或者函数集成到了一个类型中,这样就可以更为准确的去描述客观事物,比如一个狗狗,它不仅有一条大尾巴,还可以跑得非常快,大尾巴是数据,会跑且跑得快是方法。面向对象的语言比如C++或者Java,就把这些变量和方法封装起来,形成一个新的更为综合的量化工具,那就是对象。
站在C语言的基础上,往上看是C++语言等面向对象的,但是如果往下看,比如到了汇编级别,就是另外一番场景。我们知道汇编语言是最接近机器的语言,对于某一类型的单片机,它一般有几十条特定中汇编指令。但是我们说汇编语言是没有数据类型的,它操作的只有二进制类型的数据,并没有对这些数据进行按照其属性进行分类。没有根据属性对数据进行分类,其实也就是说没有对量化工具进行分类,那么人类的大脑就要耗费更多的能量去理解汇编程序,人的大脑本身都是很懒的,能省能量肯定是想办法节省能量。从这个角度上的看,汇编语言更像是机器语言。
但是我们说电脑本身就是机器,不同汇编语言的指令集才能真正反映各个芯片架构的不同,指令集不同可能对应的电路也是不同的。任何高级语言最后还是要在特定的机器上运行的,那也就是说这些高级语言最后还是要翻译成特定的汇编语言。这个翻译的工作就是编译器要做的事情。另外,软件的开发还要有量好的代码编辑环境以及调试环境(比如支持单步调试,实时查看寄存器及存储单元的数据),所以一款新的单片机是不是好用会有多方面的因素影响的,也不能只看指令集的执行效率。
第二个问题,C语言都有什么类型的变量呢?我们可以用一张表来大概描述一下,下面这张表对C语言的数据类型进行了相对完整的总结。大家可以看一下,整体的数据类型被划分为四类:基本类型,构造类型(组合类型),指针类型还有空类型。基本的数据类型肯定是根本,C语言在级别数据类型的基础上构造出更为复杂的数据类型,用于描述相对复杂的事物,比如结构体等等。那么C语言就是使用这些相对抽象的基本类型,去量化和描述纷繁复杂的外部世界的。我们在前面已经提到了绝大多数数据类型产生的原因,这里就不再赘述了。如果有还不理解的同学,可以自己上网去查一查资料。
从下面这幅图可以看出,不同的基础数据类型器长度是不一样的,而且同一种数据类型在不同的机器和编译器编译下其数据长度也是不一样的。不同的基础数据类型,所占据是二进制数据位数发生不同,这个是可以理解的。对于相对简单的事物,比如字符,本来就不需要使用那么长的位数来表达,这个是基本诉求。再一个,比如对于char类型这种需要较少位数就可以表达的可以量化的事物,如果使用int这种长度的数据去表达,本身也是对计算机存储资源的浪费。基于上述两个原因,才出现了不同的数据类型有不同的长度的现象。我们在实际编程的时候,从设计的角度上来看,肯定是选择使用最少的存储位数来量化自己要描述的事物,这样占用的资源才能是最少。当程序代码行数非常多的时候,这种差异就会相对非常明显了。
下面,我们来探讨第三个问题,变量为什么要初始化以及如何初始化。我们首先解释一下为什么单片机数据最好要初始化。众所周知,变量是存储在RAM中,掉电后即丢失,上电后默认全为0。那么这样的话没赋初值的变量值全为0,这也应该是大家认为理所当然的。但是实际上并不是这样,有些类型的单片机,当单片机复位的时候(包括硬件复位即按下复位按钮,看门狗复位,以及其它软件程序复位),单片机只是重新跳回到main函数开始执行,而并没有清空RAM!所以,那些只是定义而没有赋初值的变量(尤其是全局变量)依然会使用复位前留下来的值!那么这样,程序运行可能就会出现异常的结果,尤其是指针变量。数据有一个初始的值,整个程序也就有了一个初始状态,初始状态确定了,如果程序设计得没有问题,那么就可以按照既定的规则跑下去。如果程序错误发生在初始位置上,那就太可惜了。大家在编程的时候,一定要注意这个现象。
那么下面我们看一下,如何对变量进行初始化。不同的变量类型,初始化的方式肯定是不一样的。首先对于基础的数据类型,可以直接初始化成想要的值即可。那么对于数组、结构体等类型,初始化的方法就具体问题具体分析,各具特色了。我们下面举例子进行说明。
一维数组:
int a[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int a[10] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
int a[10] = {0};
int a[] = {1, 2, 3, 4, 5};
二维数组:
int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
int a[3][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
int a[3][4] = {{1}, {5}, {9}};
/*
1 0 0 0
5 0 0 0
9 0 0 0
*/
int a[3][4] = {{1}, {0, 6}, {0, 0, 11}};
/*
1 0 0 0
0 6 0 0
0 0 11 0
*/
int a[3][4] = {{1}, {5, 6}};
/*
1 0 0 0
5 6 0 0
0 0 0 0
*/
int a[][4] = {{0, 0, 3}, {}, {0, 10}};
/*
0 0 3 0
0 0 0 0
0 10 0 0
*/
字符数组:
char c[10] = {'I', ' ', 'a', 'm', ' ', 'h', 'a', 'p', 'p', 'y'};
char c[2][3] = {{'y', 'o', 'u'}, {'a', 'r', 'e'}};
char c[] = {"I am happy"};
char c[] = "I am happy"; // 可以省略花括号
char c[] = {'I', ' ', 'a', 'm', ' ', 'h', 'a', 'p', 'p', 'y', '�'}; // 与上面等价
char *p;
p = "I love China"; // 正确
char c[14];
c = "I love China"; // 错误
c[14] = "I love China"; // 错误
结构体:
struct {
char name[20];
int age;
}student1, student2;
//匿名结构体
struct Student {
char name[20];
int age;
}student1, student2;
//声明结构体
struct Student {
char name[20];
int age;
}student1 = {"xiaoming", 20};
struct Student student1={.age=12}; // C99可以只对age进行初始化,其他变量初始化成零
联合体:
union Data {
int i;
char ch;
float f;
}a = {1, 'a', 1.5}; // 错误,不能同时初a.ch = 'A'; // 正确
对共用体赋值要指明赋值对象,如
a.f = 1.5; // 正确
a.i = 40; // 正确
a = 1; // 错误,没有指明赋值对象始化3个
union Data a = {16}; // 正确
union Data a = {.ch='j'}; // 正确 C99新增
枚举:
第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。
声明
enum Weekday {sun, mon, tue, wed, thu, fri, sat};
定义
enum Weekday workday, weedkend;
赋值
enum Weekday {sun=7, mon=1, tue, wed, thu, fri, sat};
// sun=7, mon=1, tue=2, wed=3, thu=4, fri=5, sat=6
把上述三个问题到搞清楚后,我们的这篇文章到此就结束了。
参考资料
① C语言数据类型总结 https://blog.csdn.net/xingjiarong/article/details/46942649
② C++继承 https://www.runoob.com/cplusplus/cpp-inheritance.html
③单片机C语言探究--为什么变量最好要赋初值 https://blog.csdn.net/weixin_34342207/article/details/92999746
④ C语言-定义与初始化总结 https://blog.csdn.net/syzdev/article/details/103532435

大家好,我是张飞实战电子张角老师!
现在是一个万物互联的时代,既然要实现万物互联,各个物联网设备之间的通信就是一个不可回避的问题。我们常用的单片机的接口比如spi,i2c,uart等等,都属于有线连接,而且寻址和传输协议也相对来说比较简单,这也就决定了它们的主要适用范围主要是板级通信,传输速度不会太远。有线连接中,能够实现较远距离传输的,就是网络接口。借助互联网基础设施中的路由器、交换机以及光纤等转接和传输设备,基于复杂的TCP/IP协议栈,人类构建了庞大的互联网体系,并在此体系上衍生出了各种各样的应用,极大地提供了人们获取信息的速度。
但是,随着越来越多的设备都需要连接在网络上,进一步提高设备的在线能力,只靠有线通信已经越来越不能满足需求。所以无线通信技术蓬勃发展起来,这里面比较常见的通信协议,包括wifi,蓝牙,zigbee,2G,3G,4G,5G等等。这些无线通信协议,都有着自己的技术优势和劣势,以及时代性。目前来看,除去运营商覆盖的网络或者说移动通信网络(2G,3G,4G,5G等)外,最为常用的就是wifi和蓝牙通信技术,它们可以被认为是近距离通信(或者说固定无线通信)的解决方案中的佼佼者,比如我们的手机上一般都会配有wifi和蓝牙通信模块。其中wifi通信,因其天然具有连接互联网能力,所以应用范围更为广泛。
总体上来说,Wifi和蓝牙通信技术各有各的优势,wifi通信传输的数据量比较大,但是功耗高;蓝牙通信技术,数据传输速度相对要慢一些,但是功耗低。
另外,Wifi覆盖的范围相对蓝牙来说也更为广泛,覆盖半径可以达到300m,在家庭和办公室使用肯定是可以的。随着wifi技术的发展,有些wifi网络甚至可以覆盖整个办公大楼。蓝牙则不同,它的覆盖范围往往只有十几米。在频段上,蓝牙一直工作在2.45Ghz这个频段;但是Wifi目前有两个频段范,一个是2.4G频段,一个是5G频段。从上面的描述可以看出来,wifi要实现这些功能,具备强悍的穿墙能力肯定是必须的了,但是他们的工作频段是却是一样的,那么一个重要的区别就是他们的功率不一样了:Wifi的功率相对来说非常大,所以能够穿墙。如果从功耗方面来讲,设计10m有效传输距离的蓝牙模块,其功耗只有2.5mW左右,指望它实现穿墙功能,也是难为它了。
但是蓝牙的超低功耗对于其在电池供电的场景中的使用,提供了非常具有竞争力的优势,所以很多智能门锁主要的通信手段是蓝牙通信。因为Wifi通信功耗太高,一般不太适合电池供电的场景中。
我们今天着力分析物联网应用中的wifi模组。那么我们这里遇到的第一个问题,就是为什么我们这里提到的是模组,而不是模块呢?wifi模组和芯片有什么样的区别呢?单纯从名字上来看,wifi模组包含的东西就要比芯片要多。多出来的东西主要是什么呢?一般来说,主要是RF射频模块,存储芯片以及Wifi协议栈的实现。RF射频模块的开发,对信号质量,信号完整性都要求比较高,当然其开发难度也比较大,需要的设备也比较多。这个对小批量产品或者需要快速出货的产品,是一个极高的成本。另外,对一些技术能力较弱的公司,也是一个门槛。因此,市场上就出现了专门生产模组的公司,他们利用自己的技术实力把wifi芯片+存储芯片+射频模块等封装在一起,形成一个统一的解决方案。然后再通过通过商业营销,通过大规模的出货,去平摊他们的研发成本,并从中赚到一定的利润。这对物联网的开发者以及他们自己来说,都是一个双赢的方案。如果某款产品的出货量确实非常大,得到了市场的验证以后,这个时候它的开发者有能力也有动力去选择自己去开发wifi模块,去进一步降低成本或者作出更具特色的解决方案。实际上,从商业的角度讲,一般情况下使用通用的wifi模组可能成本更低,因为它的出货量更大。再一个,这些通用的WiFi模组,在实际应用中可能已经经历过各种各样实际场景的检验,进而模组的厂家可能会有不断的产品迭代,所以它的稳定性应该更为可靠。当然这些都是建立在选对wifi模组的基础之上的,如果选错了产品,可能就会适得其反。
那么我们该如何使用wifi模组呢?这里有两种方式,一种是直接使用wifi模组内部的单片机进行控制及数据采集功能的实现,不过模组内部的单片机一般情况下,性能相对来说没有那么强大而且引脚数量也受限,所以这种方案只能用在功能简单的场景中。再一个,是我们自己根据实际功能的需求,选择匹配的单片机;wifi模组呢,只是作为一个透传的工具而已。具体怎样使用,可以根据自己的实际情况来确定。
不管实现方式有何不同,wifi模组的使用者一般都只能使用AT命令来操作模组里面集成的wifi模块。当开发者参照模组说明,使用AT指令操作wifi模组时,wifi模组就可以按照命令进行正确的工作,比如联网什么的。
那么我们刚才提到的透传是什么意思呢?一般情况下,我们的主控单片机和wifi模组之间使用的是UART通信,主控单片机通过UART接口发送AT指令给我们的wifi,wifi模组收到指令之后,就按照AT指令的内容进行工作了。因此,从表面上看,我们的wifi模组好像不存在一样,就像我们使用uart接口在进行联网操作。这种场景下,wifi模组可以理解为一个透传模块。因为这种使用方式,我们需要使用两个单片机,相对来说成本比较高一些。但是因为我们要实现相对复杂的功能,如果wifi模组内部的单片机实现不了我们想要的东西,这个也是一个没有办法的选择。
这里我们拿市场上比较火(使用相对来说较为简单,或者说可能出货量比较大)的一块wifi芯片ESP8266来举例,它自己的内核本身就是一款32位的MCU,内核是Tensilica L1o,采样的是cortex-M3的架构,主频高达135Mhz,有一个32位的乘法器,一个定时器,15个中断。对于简单的IOT产品,ESP8266完全可以兼任MCU主控的工作,这样可以进一步降低成本。
基于这款芯片的模组,淘宝上卖得比较火的比如深圳安信可的ESP-12F等,就是在这款芯片的基础上额外封装了外置存储芯片和RF模块等等。对于较为简单的IOT应用,我们当然是可以直接使用它内部的单片机来实现相应的功能。
从图上可以看出这款模组使用的是板载天线,也就是上图中板子边缘上的金色的线条部分。经过相关资料查询,它的WiFi传输距离可以达到80米,SPI Flash的存储空间是32Mbits,总共有9个IO口。更为详细的参数表格,大家可以参考下图。

大家好,我是张飞实战电子张角老师!
通过这个电源,我们就可以得到12V的电压了,然后我们可以通过线性电源,比如7805把这个电压降压到5V,然后在再通过AMS1117把5V电压降压到3.3V。这种方案适用于产品开发中,我们甚至可以自己开发一块反激电源放在我们的产品的板子上。因为实际的环境中,可能只有AC 220的电源。对于一些极端的情况,比如AC 220V不能够达到的地方,有的物联网产品甚至只能是太阳能供电,当然这个电源是另外一个方案了。
一般情况下开发板则不同,只是大家学习的工具,对吧。那么供电部分的方案,自然也是不同的。比如我们就可以从我们的笔记本或者台式机上的USB口上获取电源。这样我们就利用了电脑自己的电源模块,是吧。AC降压的部分是电脑自己完成的,我们这里的方案是站在它的基础上的。USB电源的输出电压是5V,一般情况下,这个5V电源的输出能力可以达到500mA左右,可见它的功率还是蛮大的。
上面我们只是分析了大体的情况,那么具体到我们这个开发板中,这些大体的方案合适么?我们下面来具体分析一下。
首先我们来看一下,我们的这个模组的供电要求,从下图可以看出这个模块要稳定工作,供电电流要大于500mA。但从这一个数据来看,我们就没有办法仅仅使用一个USB来供电,那样单片机有可能就不可以正常工作,我们这里说得是有可能呀,也不一定不能工作。但是从产品设计的角度来看,如果只用一个USB接口来供电,这样的设计是不稳妥的。
我们今天使用ESP8266这款芯片设计一块物联网开发板,使用的模组是ESP-12F,这款模组我们在上篇文章已经给大家介绍过,生产厂家是深圳是安信可科技有限公司。我们这款开发板,只是使用这个模组内部的单片机ESP8266,实现的功能来说也相对较为简单,换句话说,也就是没有外挂单片机。
那么总体上要实现什么功能呢?
第一个要实现的功能是温湿度的采集,这个是物联网场景中最为常见的。远程而且在线的数据采集功能,能够为系统决策提供实时的决策依据。我们这里主要是以温湿度的采集以及往云端上传为例,给大家演示一下物联网开发板的流程是什么样子的。
第二个要实现的功能是远程控制继电器的开关。我们从物联网的数据终端获得了数据之后,自然需要根据数据做出决策。那么这个决策执行,一个最简单的示例就是继电器的开通和关断。我们可以通过继电器的开通和关断,来决定相应的模块是不是需要运行。
ESP-12F这个模组要想能够正常工作,首先就是要搭建一个单片机的最小系统。这个最小系统包括如下模块,比如电源模块,程序烧录模块,时钟模块,Reset模块,boot选择模块等等。只有这些模块工作正常了,ESP-12F内部的单片机才有可能工作起来。
我们下面分别来看一下,这些小模块用什么样的方案实现比较合适。
第一个是程序烧录模块,我们这里使用的是USB转串口,芯片是CH340G,这个是南京沁恒公司出品的,属于非常常用的芯片,性能稳定价格相对便宜。具体的电路设计也相对来说比较简单。大体的电路设计如下:
我们这里只是参考示意图,具体电路实现,我们后面再分析。
第二个是时钟模块,我们这个ESP-12F里面应该已经包含了时钟震荡电路,我们不用再外接震荡电路模块。从模组管脚功能的描述上看,ESP-12F也没有外部晶振的接口,那么我们可以断定这个模组已经自己搞定了震荡器部分,要么是单片机内部的RC震荡器,要么是模组封装的石英震荡器。后面有机会,我们再对这块进行分析。
Reset模块和BOOT模块按照芯片给出的说明来就可以了。RESET这个地方一般是低复位,意思也就是说这个管脚在低电平的时候,芯片内部执行复位操作。BOOT引脚,从上图也能看出,IO0为低的时候,单片机处于下载模式。如果要让单片机处于运行模式,这个引脚必须拉高或者悬空。那么我们进行电路设计的时候,按照芯片的说明操作就可以。
再一个就是电源模块,很显然ESP-12F这个模组要能够正常工作,它一定是需要电源的。那么这个电源电压是多少呢?我们来看一下ESP-12F的datasheet。
这张表里面,我们是不是可以看出来这个模组的供电电压是不是3.3V呀,Io口的最大电流驱动能力是12mA对吧。Vil和Vih表示输入低和高的电平值,从datasheet上可以看出来输入为低的时候,最低值是-0.3V,最大值是0.25倍的Vio;输入为高的时候,最低值是0.75倍的Vio,最大值是3.6V。Vol的最大值是0.1倍的Vio,也就是说作为输出且输出为低的时候,它的最大值0.1倍的Vio;Voh的最小值是0.8Vio,这句话的意思是,IO口作为输出,且输出为高的时候,它的最小值是0.8倍的Vio。了解了这些参数,可以对我们进行外围电路的设计起到指导作用。
那么这个3.3V的电压从哪里来最合适呢?我们这里有两条思路,一条思路是从AC 220V上通过反激电源降压到12V,然后再从12V降压到3.3V;另外一条思路是利用USB接线的5V电压,直接变换成3.3V。第一种方案,我们首先要买一个12V的电源适配器,如下图所示。
通过这个电源,我们就可以得到12V的电压了,然后我们可以通过线性电源,比如7805把这个电压降压到5V,然后在再通过AMS1117把5V电压降压到3.3V。这种方案适用于产品开发中,我们甚至可以自己开发一块反激电源放在我们的产品的板子上。因为实际的环境中,可能只有AC 220的电源。对于一些极端的情况,比如AC 220V不能够达到的地方,有的物联网产品甚至只能是太阳能供电,当然这个电源是另外一个方案了。
一般情况下开发板则不同,只是大家学习的工具,对吧。那么供电部分的方案,自然也是不同的。比如我们就可以从我们的笔记本或者台式机上的USB口上获取电源。这样我们就利用了电脑自己的电源模块,是吧。AC降压的部分是电脑自己完成的,我们这里的方案是站在它的基础上的。USB电源的输出电压是5V,一般情况下,这个5V电源的输出能力可以达到500mA左右,可见它的功率还是蛮大的。
上面我们只是分析了大体的情况,那么具体到我们这个开发板中,这些大体的方案合适么?我们下面来具体分析一下。
首先我们来看一下,我们的这个模组的供电要求,从下图可以看出这个模块要稳定工作,供电电流要大于500mA。但从这一个数据来看,我们就没有办法仅仅使用一个USB来供电,那样单片机有可能就不可以正常工作,我们这里说得是有可能呀,也不一定不能工作。但是从产品设计的角度来看,如果只用一个USB接口来供电,这样的设计是不稳妥的。
另外一个耗电较大的是继电器,我们这里的继电器选定的是SRA系列的,线圈的开通电压,我们可以选择12V。那么我们来看一下,这个继电器的线圈需要多大的电流。
从上图中可以看出来,这个电流要50mA,是吧。
我们下面来看一下CH340G的功耗情况。从下表可以看出来,它的功耗最大值是在20mA左右,这个器件待机状态的时候,功耗更低,只有0.2mA左右。
SHT20(温湿度检测芯片)和其他一些LED等的模块加起来,功耗应该不会超过10mA。这样算下来,这个开发板需要的总的供电能力,差不多在600mA左右。如果再留有一点余量的话,那么我们选用的反激电源适配器,它的输出能力差不多要在1A左右。
从上面情况来看,USB供电是肯定不合适的。我们这个开发板,不适合USB供电,只能是使用适配器从AC 220V上引电下来。
有了12V电源以后,我们第一步要做的事情,就是把12V电压变成5V的,常用的器件就是LM7805。我们来看一下LM7805的输出能力,从下图中可以看出来,它差不多有1A的输出能力,是吧。这个能力是可以满足模组功耗需求的。但是我们可以计算一下它自身的功率。 P = (12V – 5V)* 500mA = 3.5W,也就是说仅仅带载ESP-12F这个板子,就需要3.5W的功率。这个对LM7805的封装来说是不可以承受的。即使加上散热片,也难保散热片不烫手,这个功率太大了。那怎么办呢?我们这里只能选择能效比更好的电源方案,比如开关电源。我们可以选择一个buck降压方案。这个buck电路,可以直接从12V降压到3.3V,也可以从12V先降压到5V,然后再通过LDO模块把电压从5V降低到3.3V。这两个方案,我们可以都用一下,看一看哪个更合适。为什么一般情况下,单片机前端电源一般采用LDO(比如AMS1117等)呢?主要是LDO输出的电压精度比较高。还有一个,如果Buck电源坏掉了,buck上的高压信号,一般也不会直接伤到单片机,中间还有一个LDO电源起到了隔离作用。另外,Buck电路输出的电压文波率相对来说也比较大,一般在2%-5%左右,这个波动对单片机的工作也会有影响。但是呢,现在的单片机一般也是宽电压输入,就像我们这个ESP-12F,它的输入电压可以从3.0V-3.6V。Buck的文波率按理说应该是可以满足要求的。我们这里可以把两个方案都试一试,通过跳线帽或者0欧姆电阻的方式选择供电电源。一个是测试一个LDO电源(AMS1117)的发热量怎么样,再一个看看buck电源能不能满足单片机的需求。
那么我们这里还需要一个5V到3.3V的电压变换,我们这里也选择最为常用的AMS1117。这个片子上面的功耗也是蛮大的,P = (5V – 3.3V)* 500mA = 0.85W。我们需要对这个片子的散热做一些特殊的处理,比如在地上需要大面积敷铜或者加散热片。我们这里AMS1117选择SOT223的封装,等板子搞好之后,实测一下温升能有多少。buck芯片我们采样SY8120 DCDC的片子,具体buck电路的设计,我们有机会展开来讲。
讲完了单片机的最小系统,我们看一看器件封装的一些问题。
对于各个器件原理图和PCB的封装,站在开发板这个需求程度上,我们可以直接采用立创上给出来的。但是如果实际做产品的时候,元器件pcb的封装,我们就要格外注意了。pcb的封装要和实际生产工艺匹配起来,这样才能最大程度上降低生产成本,进而能够降低产品总的成本。比如封装不能过大,否则可能就会有立碑现象;再比如,如果封装大小不合适,虚焊的可能性就会加大,进而产品的质量可能就会受到影响。做产品的问题,我们暂且不说,我们先来看一下,如何直接利用立创商城提供的封装。第一步,我们要先把这些封装导出来,我们这里以DHT11为例(目前这样使用有效,后续网站可能会改版,大家留意)。
比如我们这里首先选择直接使用厂家提供的封装,点击立即使用以后,就会出现schdoc和pcbdoc两个类型的文件。我们后面把可以把它导出来,变成AD软件支持的格式。这里说一下,我这里习惯使用AD软件,可能和一些同学的习惯不太一样。如果大家直接使用立创的画图软件,也就不需要导出来了。这个地方大家酌情使用。
这些文件导出来之后,我们就可以在AD软件里面生成相应的lib文件了,以便于我们在画原理图和PCB图的时候使用。
今天关于这个开发板的分享,就先到这里。我们下篇文章会继续探讨相关原理图模块的设计。
①基于ESP8266的STM32物联网开发板设计
https://blog.csdn.net/weixin_42107954/article/details/97494269
②物联网开发板-ESP8266 https://lceda.cn/jixin003/iot_board_esp12
③ ESP8266教程-技小新 https://www.yuque.com/lingyao/jing/ob5wia
④ ESP-12F 规格书
https://item.szlcsc.com/84052.html
⑤ SRA系列继电器说明书
https://item.szlcsc.com/61221.html
⑥ CH340C datasheet https://item.szlcsc.com/85852.html
⑦ LM7805 datasheet https://item.szlcsc.com/520584.html
 张角
张角