电源
91篇文章
大家好,我是张飞实战电子张角老师!
同学们好,我们从今天开始探讨单片机C语言,我们首先从if和for等基本语句结构开始。
if和for,这两个从本质上来说,是不是C语言的两个关键字呀。那么我们为什么又把它称之为C语言的基本结构的一部分呢。要回答这个问题,我们是不是首先要搞清楚C语言的基本结构是什么?
实际上,任何结构化编程语言的基本结构都是相同的,也就是三种基本的程序结构:顺序,分支和循环。由这三者最基本的结构,可以搭建出任何我们想实现的程序结构。在狄杰斯特拉(Edsger W. Dijkstra)反复研究面条式代码(spaghetti code),并在1968年给某位编辑写了一篇著名的简信,题为《Go to语句是有害的》之后,计算机科学家Corrado Bohm和Giuseppe Jacopini证明,使用顺序(sequencing),分支/选择(alternation)和循环(iteration)这三种流程结构就足以表达所有程序的本质。C语言作为结构化编程语言的一种,其程序结构,自然也是由这三种最基本的程序结构组成。
顺序执行程序,这个很好理解,一条语句接着一条语句执行就可以了。那么C语言的分支和循环是如何实现的呢?
对于分支,我们常见的关键词是不是有if/else和switch/case两种组合呀。if/else翻译过来,是不是就是“如果…,否则…”,是一个条件判断。如果用伪代码的方式来进行表达的话,一般有这两种形式。
第一种形式如下:
if(条件为真)
{
代码段1;
}
else
{
代码段2;
}
这里else的含义其实就是条件不为真,那么也就是条件为假。
第二种形式是这样的,
if(条件1为真)
{
代码段1;
}
else if(条件2为真)
{
代码段2;
}
else
{
代码段3;
}
第一种形式和第二种形式本质上的区别,其实就是第一个是双分支,第二个是多分支。两种不同的分支,我们要根据具体情况去使用。某种意义上多分支模式可以由双分支演变而来,比如我们可以在双分支模式里面的else里嵌套一个双分支结构就可以了。
if(条件1为真)
{
代码段1;
}
else
{
if(条件2为真)
{
代码段2;
}
else
{
代码段3;
}
}
从这个意义上看,双分支和多分支其实是一回事情,本质上都是分支。分支这个概念,大家应该都是相对容易接受的,任何一件事情总有它的对立面,高对低,胖对瘦,大对小,物质对暗物质等等。分支这个概念应该是反映了事物的一种本源的状态,是描述程序是不可再进行切分的维度,也就是说分支成为了任何程序的三种基本结构之一。
其实对于多分支的情况,C语言有另外一套关键字组合switch/case,写成伪代码的形式,大概是这样的。
switch(变量){
case 常数1:
代码段1;
break;
case 常数2:
代码段2;
break;
case 常数3:
代码段3;
break;
。。。
default:
代码段n;
break;
}
大家注意没,对于switch/case组合来说,它的条件一定要是常量,而且要是整数。这个是不是对判断的条件作出了限制呀。这里的default关键字,是和if/else里面的else对应的,表示意外情况。从表面看,switch/case适用于逻辑条件简单,但是分类较多的情况;if/else适用于判断条件复杂,但是分支较少的情况。但是从另外一个层面看来,switch/case所具备的功能,if/else完成起来,完全没有问题呀。那为什么还要搞出来这一个关键字组合呢?
我个人的理解是switch/case关键字的执行效率,在某些情况下,要比if/else要高。
int a = 0;
switch(a)
{
case -1:
break;
case -2:
break;
case -3:
break;
case -4:
break;
case 0:
printf("I am in switch case!n");
break;
default:
break;
}
printf("I am between the switch case and if/else if/else!n");
if (-1 == a)
{
}
else if (-2 == a)
{
}
else if (-3 == a)
{
}
else if (-4 == a)
{
}
else if (-5 == a)
{
}
else
{
printf("I am in if/else if/else!n");
}
比如对于上面的代码段,对于switch/case关键词对来说,程序是直接跳到case为0的情况下的;但是对于if/else而言,程序则是一句一句比较之后才达到了“else”这一句,程序执行效率的高低是显而易见的。
但是我们说,switch/case的程序执行效率可以比较高,并不是没有条件的。从汇编语言的层面来看,switch/case是建立了一张跳转表,因此需要一定的空间才行。这里某种程度上有以空间换时间的意思。
因此,如果程序可以使用switch/case尽量使用这个,以便提高它的执行效率。其实,我们这样比对一番之后,自己也就轻而易举地牢牢记住了它们,这个可能也就是知其然知其所以然的效果,符合人的记忆规律。
讲完了分支,我们来看一下循环。循环这个基本结构,在C语言里面,一共有两种实现方式,for循环和while循环,其中while循环还可以分为两种,一种是while循环,一种是do/while循环。我们下面分别看一下,这三种结构的程序表达大概是什么模样。
for(循环控制变量初始化;循环终止条件;循环控制变量增量){
循环体;
}
for循环的执行步骤是:首先执行循环变量的初始化,然后执行循环终止条件;如果判断条件为假(不符合终止条件),那么就开始执行循环体;然后执行循环控制变量的增量程序,执行完以后,再去判断是不是符合循环终止条件;如何符合条件,那么就退出循环;如果不符合条件,那么就继续执行循环体,并重复执行上述步骤。
感觉用第二种方式来描述这个循环体的执行过程,更为清晰。第一,先进行循环控制变量初始化;第二,执行循环终止条件,如果判断结果为假,则进入第三步;如果为假则循环终止并退出;第三,执行循环体;第四,执行循环控制变量增量,转入第二步;
注意,其实for循环括号中的三部分其实都可以省略,如果全部省略了,就变成了一个无限循环的死循环,跳不出来了。无限循环在操作系统中使用的是非常多的,每一个任务都是一个无限循环体,包括main函数也是一个无限循环体。
下面,我们来看一下while循环的代码格式。
循环控制变量初始化;
while(循环终止条件){
循环体;
循环控制变量增量;
}
while循环的执行步骤可以描述为如下的样子。
第一在while之前,先执行循环控制变量的初始化;第二,判断循环终止条件是否成立,如果成立那么就跳出循环,如果不成立就进入第三步;第三步,执行循环体;第四步,执行循环控制变量增量,然后进入第二步。
do/while的代码格式是什么样子呢?
循环控制变量初始化;
do{
循环体;
循环控制变量增量;
}while(循环终止条件)
while循环的执行步骤可以描述为如下的样子。第一,在do(也就是执行)之前,先执行循环控制变量的初始化;第二,先执行一次循环体和循环控制变量的增量;第三步,判断循环终止条件是否成立,如果成立那么就跳出循环,如果不成立就进入第二步;
我们来看一下呀,while和do/while主要的区别,一个是先判断再执行,一个是先执行再判断,那么也就是说do/while这个关键字组合中,函数体至少执行一次。但是这并不影响while和do/while之间的转化呀,同样的功能绝大多数情况下,可以用while也可以使用do/while来实现。那么有没有必须要用do/while的时候呢?答案是有的,在linux编程中,do/while常用的一个方式是do while(0)。
比如,我需要定义一个宏:
#define SAFE_FREE(p) do{free(p); p=NULL} while(0)
假设这里去掉do{....} while(0),及定义为:
#define SAFE_FREE(p) free(p); p=NULL;
那么以下代码:
If(NULL!=p)
SAFE_FREE(p)
else
.......
会被展开成如下的有仇
If(NULL!=p)
free(p); p=NULL;
else
.......
展开之后,存在两个问题。因为if分支后面有两个语句,会导致else分支没有对应的if,编译失败。即使假设没有else分支,SAFE_FREE中的第二句,无论if测试是否通过,这个都会被执行。那么如何解决上述问题呢?有人说给SAFE_FREE的定义加上{}就可以了,比如如下的样子:
#define SAFE_FREE(p) { free(p); p=NULL; }
代码展开如下:
If(NULL!=p)
{ free(p); p=NULL; };
else
.......
这样问题又来了,else 没有对应的if了,编译还是会失败。但是使用了do while(0)则可以完美解决上述问题。代码展开如下,
If(NULL!=p)
do { free(p); p=NULL; } while(0);
else
.......
所以,do while(0)的使用是为了保证宏定义的使用者能无编译错误的使用宏。
下面我们讨论一下,为什么C语言有了for,还需要while呢?除了上面的do while(0)的必要性之外,好像还真得没有确切的其他原因。比如在golang编译其中,就只有for,没有while了;再比如,java的源代码里面,就是有一堆的for(;;),据说可以提高性能。所以更大程度上讲,C语言只是为了,兼容程序员的编码习惯,保留了while这个关键字而已。
一些更现代的语言还加入了foreach、for in这种专门遍历集合的语法糖,也有python、ruby这种直接抛弃了C语言三段式for,只保留了for in,而把非遍历型的循环统统放到while循环里面的做法。
我们这次关于程序基本结构的探讨就先到这里。
参考资料:
① 基础学习C语言第四章:三种基本结构 https://zhuanlan.zhihu.com/p/97629275
② Linux - switch/case与if/else if/else的效率比较
http://blog.sina.com.cn/s/blog_5acb430f0100ael9.html
https://www.cnblogs.com/anlia/p/11685639.html
④ 深度理解do{} while(0)
https://blog.csdn.net/weibo1230123/article/details/81904498
大家好,我是张飞实战电子张角老师!
所有通信协议,应该都是一个速度、成本的折中,这里的成本包括完成通信所占据的接口资源(或者说需要几根线)以及硬件电路模块设计的复杂度。
我们前面分析过,如果想要实现高速的数据通信,通信双方的时钟是必须同步的,否则可能会出现数据错位的情况,尤其是通信双方本身的时钟频率相差较大的时候。那么自然的,uart作为一种异步通信协议,它的传输速率肯定不会太高,或者说肯定是小于同步通信协议的。反过来说,如果异步通信协议采用采用发送方或者接受方中的一个时钟频率,作为通信的波特率,那么在两者的时钟频率相差较大的情况下,一定会出现数据错配的情况。甚至有可能,每次传递8个数据都不一定传输得了。信号传输的波特率降低了以后,可以降低对通信双方频率相差的要求,反正最后都要把自身的频率和波特率之间进行一次转换,归一到统一的波特率上来。但是归一化之后依然会有误差的,这个我们前面讨论过,所以依然不能每次传递较多的数据。再加上,uart通信协议中,各种辅助位占据了一定的资源(大约25%),数据传递的速度肯定就更慢了。
虽然uart传输的速度相对较慢,但是如果只是单向通信的话,着实相对来说,非常简单。只需要两根线就可以了,一根Tx就行(大多数情况下,通信的双方都是共地的)。
那么现在我们达成了共识,如果要进行高速的串口通信,必须在通信的双方之间进行时钟同步。那么SPI和I2C这两种协议,应运而生了。那么SPI和I2C有什么区别呢?我感觉这两个有点像TCP和UDP的区别一样,TCP有校验和握手机制;UDP则没有,只是不管不顾发数据。具体表现就是I2C是有应答机制的,但是SPI没有,那么自然I2C这种通信协议的传输速率是没有SPI快的。再一个,在I2C通信中,不管是读指令还是写指令,首先进行的是不是寻址呀,找到相应的芯片以后,才能进行下一步的数据传输,是吧。但是SPI就不用搞这个操作,它是通过硬件的片选信号之间指定从机的,从地址寻址上看,它的速度要远比I2C高。还有一个,不管是读数据还是写数据,一般都是还还要再指定寄存器的地址,然后主机才能通过SDA总线去读取从机中的数据,但是SPI一般是直接通过指令读取相应的寄存器,这中间又少了一次寻址的过程,那么有效数据传递的速度相比I2C,肯定是高了许多。
从通信双工的角度来讲,SPI还支持双工通信,那数据传输的速度就更快了,在这个方面作为半双工通信的I2C自然是更比不了。
虽然传输速度,I2C比不上SPI,但是I2C也是有自己的优点呀,那就是占用的端口资源更少。只要两根线就行了,一根数据线,一根时钟线,就足够了,就可以实现双向通信了。但是SPI可不行了,SPI要实现这种双向通信,至少需要四根线,CLK,MOSI,MISO,CSS。俗话说,一分价钱一分货,此言不虚。
I2C和SPI都是可以实现点对多点进行通信的,既然要实现点对多点进行通信,那么就必须解决寻址的问题。SPI,我们说过了,仗着自己数据传输速度快的优点,财大气粗,对每一个从机都安排了一个片选信号线。这种操作,着实占用了不少单片机的接口资源。但是I2C就不行了,因为数据传递的速度相对较慢,自然得节省开支,包括在点对多点的寻址上也是如此。I2C通信协议是通过地址码的方式来解决多机寻址问题的,这个就有点像SPI的片选线。
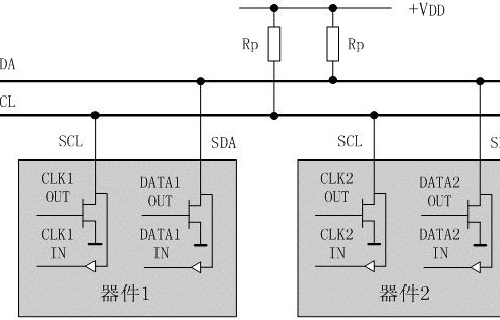
系统中的所有外围器件都具有一个7位的"从器件专用地址码",其中高4位为器件类型,由生产厂家制定,低3位为器件引脚定义地址,由使用者定义。主控器件通过地址码建立多机通信的机制,因此I2C总线省去了外围器件的片选线,这样无论总线上挂接多少个器件(当然终端在要在有效个数范围内),其系统仍然为简约的二线结构。终端挂载在总线上,有主端和从端之分,主端必须是带有CPU的逻辑模块,在同一总线上同一时刻只能有一个主端,可以有多个从端,从端的数量受地址空间和总线的最大电容 400pF的限制。
基于IIC总线的物理结构,总线上的START和STOP信号必定是唯一的。如果同时又两个设备同时发起数据传送怎么办?这就涉及到时钟同步和SDA仲裁的问题。我们这里注意到SDA和SCL都是开漏输出设计,那么自然SDA和SCL都具有线与功能。在SCL总线上只有所有的设备的SCL都为高的时候,SCL才为高,只要有一个为低,那么SCL就为低。不管怎样,所有从设备设备的SCL总是同步的。要么是高,要么是低。
那么SDA的仲裁问题是怎么回事呢?SDA线的仲裁也是建立在总线具有线“与”逻辑功能的原理上的。节点在发送1位数据后,比较总线上所呈现的数据与自己发送的是否一致。是,继续发送;否则,退出竞争。这里的比较功能是I2C设计的亮点,有了这个功能为基础,SDA的总线仲裁才能是自动执行的。SDA线的仲裁可以保证I2C总线系统在多个主节点同时企图控制总线时通信正常进行并且数据不丢失。总线系统通过仲裁只允许一个主节点可以继续占据总线。
上图是以两个节点为例的仲裁过程。DATA1和DATA2分别是主节点向总线所发送的数据信号,SDA为总线上所呈现的数据信号,SCL是总线上所呈现的时钟信号。当主节点1、2同时发送起始信号时,两个主节点都发送了高电平信号。这时总线上呈现的信号为高电平,两个主节点都检测到总线上的信号与自己发送的信号相同,继续发送数据。第2个时钟周期,2个主节点都发送低电平信号,在总线上呈现的信号为低电平,仍继续发送数据。在第3个时钟周期,主节点1发送高电平信号,而主节点2发送低电平信号。根据总线的线“与”的逻辑功能,总线上的信号为低电平,这时主节点1检测到总线上的数据和自己所发送的数据不一样,就断开数据的输出级,转为从机接收状态。这样主节点2就赢得了总线,而且数据没有丢失,即总线的数据与主节点2所发送的数据一样,而主节点1在转为从节点后继续接收数据,同样也没有丢掉SDA线上的数据。因此在仲裁过程中数据没有丢失。
这里大家注意一下,SCL同步与SDA仲裁是同时发生的,不存在先后问题。这些实现都是由于I2C设备的特殊设计实现的,堪称非常优雅。
大家好,我是张飞实战电子张角老师!
在单片机开发过程中,我们常用的通信协议主要有UART,SPI,I2C这几种,是吧。这三种通信协议,本质上都是串口通信,也就是说在一个时钟周期中,只发送一个数据位。顾名思义,如果在一个时钟周期里面发送多个数据,是不是就是并行通信了,并行通信,自然需要更多的数据线,进而会占据更多的资源。不过并行通信的好处也是显而易见的,也就是说单位时间内(或者说一个时钟周期内)可以传递更多的数据,比如在大屏显示这种通信类型的时候,一般就需要使用并行传输协议。没办法呀,数据量太大,不得不如此。但是在相对低速的通信场景中,串口通信能够满足绝大多数的需求,所以在单片机的外设资源中,串口通信占据了不少份额。
我们首先来分析一下串口通信的原理。串口通信的接收过程,大概就是上图中描述的样子。这个图中我们只是使用三个数据来示意表达。DSR发送过来的“010”这三个数被移位寄存器移位以后,通过“D1,D2,D3”并行输出。实际上一般这里是8个D触发器,实现8个串行数据的并出效果,单片机的最小存储单元一般是8个bits么。发送端实现的一般是“并入串出”,只是方向反过来了,原理和上面的一样的。上图中N管和P管组成的电路是为了上电的时候,对D触发器的数据进行复位,这个地方大家不必太在意。
在UART、SPI和I2C这三种最为常用的串口通信中,以UART的实现最为简单,通信的双方不需要严格的时钟配合,只需要设定好波特率就可以了。所谓不需要严格的时钟同步,也就是说通信的双方可以使用各自的时钟,通信双方的时钟频率不一定相等,我们在使用UART进行数据通信的时候,每次发送的数据最长是8个bits,可以比这个短,但是不能再比这个长了。如下图所示,数据位可以是8/7/6三类。那究竟是为什么呢?一次发送多个数据不行么?
异步通信可以允许通信的双方具有一定的时钟误差,时钟误差越大,每次能够发送的数据位数就越短;时钟误差越小,每次能够发送的数据长度也就越长。为什么是这样呢?假定对于主机,一个bit对应的脉冲数正好是10个,对于从机一个bit对应的脉冲数是10.2个。那么随着bit数的增多,比如达到5个bit的时候,从机就会出现有51个脉冲数,那多出来的一个脉冲数该怎么对应呢?电路设计上该怎么设计呢?换句话说,就会出现数据错位。从这个例子来看,只要从机和主机时间频率上有误差,随着单次数据传递量的增长,那么一定会有数据错位出现。这个也就是UART进行数据传输的时候,一次只传输一个byte,主要的目的就是为了防止出现数据错乱的情况发生。
我们下面用图形化的方式来说明一下这个问题。
如上图所示,PWM1和PWM2是两个不同的时钟信号,大家可以看一下这两个时钟的周期明显是不一样的。我们让这两个时钟都同时从A时刻起步,大家可以看一下,到达B时刻的时候PWM1和PWM2已经反相了,到达C时刻的时候PWM1和PWM2又变成同相了。大家可以看一下,到达C时刻的时候,PWM2的周期数已经比PWM1多了一个了,那么多出来的这个时钟周期就会出现无法和数据位匹配的情况。反过来对于数据来说,也就是会出现数据错乱的现象。
但是SPI和UART通信的双方有一条时钟线相连,通过这条时钟线他们实现了严格的时序匹配。因为双方时序完全一致,那么在数据采样、移位以及存储的时候,就不可能出现数据错乱的情况。某种意义上时钟有多快,数据传输的速度就会有多快。当然实际应用中,SPI和I2C数据传输的速度,还受到通信接口本身器件特性(结电容)、CPU处理数据的速度、存储器存储数据的速度以及布线等因素的影响,具体的数据传输速度是考虑了诸多因素之后确定的一个值,我们需要具体应用具体分析。
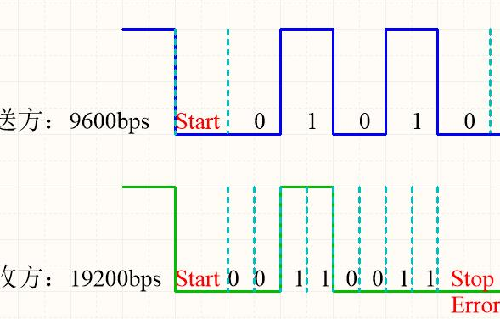
对于Uart来说,为什么通信双方的波特率需要设置的是一样的呢?波特率是不是就是数字信号采样的速率,如果通信双方采样的速率不一样,很显然会导致错误的结果。我们假定UART发送方的波特率是9600,接收方的波特率是19200。发送方发送的数据是“0101 0001”,那接收方会接收到什么数据呢?我们这里接收方数据采样的速率是不是发送方的两倍呀,大家可以看下面的图。
接收方数据采样出来的数据是不是“0011 0011”呀,是不是发送方的每个数据才接收方采样了两次呀,而且停止位是不是还出现了错误。这个例子从侧面说明了,发送方和接收方波特率必须一致的原因。
异步通信,相比同步通信,还有一个缺点,那就是说信号传递的速度相对较慢。在UART协议中,每个字符都需要起始位和停止位作为字符和开始和结束的标志,另外还有一个校验位,这些辅助设施大约增加了20%的信息位,以至占用了信号传输的时间,所以通信的速度就上不去。
对UART通信过程的探讨,我们先到这里。
大家好,我是张飞实战电子张角老师
讲完了基本的外设接口,我们今天看一下这个开发板的中断系统。中断系统可以说是单片机能够响应任务需求的核心机制,对于一个固定的单片机而言,计算资源只有那么多,如何高效地利用这些计算资源,是单片机设计者必须回答的问题。目前主流的方案,就是我们今天要讲的中断系统。我们可以人为给不同的中断请求设定不同的级别,这样单片机系统就知道执行任务的轻重缓急了,系统的实时性提高了,计算资源就相当于被高效地利用了。
那么,在嵌入式实时操作系统中,任务又是一个什么概念呢?我们知道,任务也是有优先级的,不同的任务优先级是不同的,那任务的优先级和中断的优先级是什么关系?我觉得,可以把任务理解成一种不靠硬件抢占执行的中断,应该归入大中断的概念中去,本质上是进一步提升了单片机响应任务的实时性。我们知道,一般中断程序的执行时间都不宜太长,只是负责变量打标,然后快速退出就可以了。一个高中断优先级的中断程序,执行得太长的话,那么所有相应的低优先级的中断程序是不是就完全无法执行了。所以程序开发的时候,才尽可能地让中断程序只是负责对变量打标而已。中断程序对相应的变量打标以后,实际工作的执行,还主要是任务的调度来实现的。这样的设计,相比而言能够让计算资源的实时性得到最大程序的发挥。这个也是嵌入式实时操作系统被设计出来的一个关键的原因。
鸿蒙系统外部中断,到底是怎么样被初始化的呢?
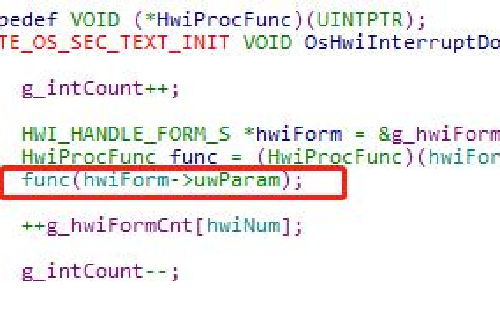
上图中,第一个红框里面代码的意思就是开中断,这样单片机的各种硬件中断就可以进行响应了。这段代码执行以后,使用鸿蒙系统的中断创建函数创建外部中断。
我们先不看外部中断内部是怎么实现的,先看一下这个中断创建函数是怎么工作的。在STM32中,中断函数能够被执行,是因为中断函数的地址或者叫做向量被放在中断向量表这个地方。当有外部中断请求发生的时候,单片机的硬件电路就会自动寻址到相应的中断函数,进而进入到函数里面去执行相应的代码。当然这中间肯定伴随着各种环境参数的保存,环境参数的保存,主要是为了解决从中断中恢复的时候,程序找到回去的路。
鸿蒙系统的中断创建函数,所做的主要事情,如下图所示,就是把一个数组g_hwiForm里面的数值初始化了。
这个数组里面的每一个数值存放了相应中断函数的地址以及相关的参数值。我们可以暂且认为这个数组存放的就是中断向量表,那这些个函数是怎么执行起来的,或者说是如何被调用的呢?
我们看一下,我们这款单片机的中断执行机制。RISC-V单片机中断向量表的起始地址,是由CSR寄存器mtvt来指定的,具体说明,如下图。那也就是说当有外部中断触发的时候,单片机硬件查询的首先是这个寄存器的地址,然后执行这个寄存器中的地址所指向的代码。那么我们的鸿蒙系统中,有没有对这个寄存器进行初始化呢?
大家可以看一下,实际上在操作系统启动的汇编代码部分,这个向量是被初始化了的。如下图,操作系统把TrapVector函数地址放入了t0,然后把t0放入了mtvec这个寄存器中。那TrapVector到底是什么呢?
大家看一看,这个TrapVector函数里面,在经过一系列的寄存器操作以后,调用了OsHwiInterruptDone和TaskSwitch这两个函数。这也就是说每次中断请求发生以后,都会执行这两个函数。
这个OsHwiInterruptDone函数地址里面,是不是就调用了我们初始化的中断函数呀。它根据不同的中断号码执行不同的中断函数,如下图所示。
在本篇文章刚开始的时候,我们是不是提到的外部中断响应函数OsMachineExternalInterrupt,如果有外部中断发出请求的话,就会进入到这个函数中去。
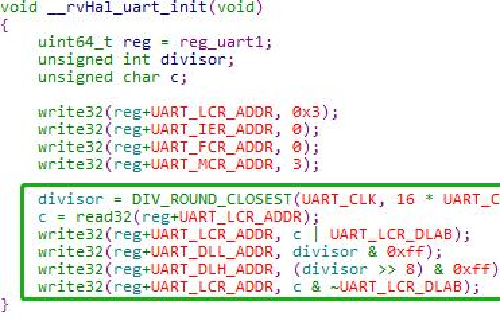
讲完了I2C接口,我们下面来看一下UART通信相关的配置。UART接口是GPIO复用功能中最常用的一种硬件通信方式。如果只是单线通信的话,只需要一根数据线就够了,所以我们经常使用uart接口输出程序中的变量,进行调试。
在这块开发板中,对uart接口进行初始化的函数如下图所示。对UART接口配置,一个非常关键的参数就是波特率的配置。下图中,绿色部分一大块内容都是对波特率配置的程序段,可见其相对来说比较复杂,我们不需要去关注这些实现的细节,实际使用的时候拿过来用就好了。
下面,我们对相关的寄存器进行简要的介绍。
LCR:Line Control Register是线控制寄存器,所谓线控制器,主要是用于配置和传输相关的一些参数。比如,第4位是用来做奇偶校验配置的,第0-1位是用来控制一次传送多少个bits的。
IER: Interrupt Enable Register,这个是中断控制器主要控制和UART相关的中断操作的,是不是允许相应的中断。
FCR:是用来控制FIFO 相关的参数的。我们这里不使用FIFO,所以要把它禁止掉。和FIFO相关的参数,这里就不给大家展示了。
MCR,全称是 Modem Control Register,也就是和调制解调相关的寄存器。我们这里配置的两个位一个是RTS(Request to Send),一个是DTR(Data Terminal Ready)。这两个位,我们在实际使用串口的时候也会经常用到,但是实际一般不配置相应的握手协议。
配置好寄存器之后,就要开始发送数据了。数据的发送,主要是THR这个寄存器。THR的全称是Transmit Holding Register。实际发送数据的时候,只需要往这个寄存器里面写入数据就可以了。写入数据之后,UART相关的电路,自动发送数据给接收端。
上面就是这块开发板中关于UART配置的简要介绍。整体的思路和STM32的配置是相同的。新思科技的uart外设提供了非常多的寄存器进行的配置,更加贴近底层,但是这需要我们对uart的电路实现以及相关协议进行更加深入的理解才能驾驭得了。
 张角
张角